Im vorherigen Kapitel hatten wir abgeleitete Kennzahlen auf der Ebene von einzelnen Schach-Positionen und Zügen definiert, diese berechnet und in der Datenbank-Tabelle da_position gespeichert.
ACPL
Darauf aufbauend werden wir nun wie angekündigt weitere Statistiken erstellen, immer bezogen auf eine ganze Schachpartie, und beginnen dabei mit dem ACPL-Wert, welcher die durchschnittliche Abweichung in Centipawn-Einheiten vom jeweils besten Zug berechnet. Kleine ACPL-Werte legen nahe, dass vorwiegend gute Züge nahe am Optimum von der entsprechenden Seite gespielt wurden.
Wir werden die ACPL-Werte für beide Seiten berechnen, da wir auch daran interessiert sind, wie gut die Gegenspieler in den betreffenden Partien agierten.
Betrachten wir dazu eine zufällige Partie aus unserem Fundus, indem wir die einzelnen Positionen/Züge mit den zugehörigen Kennzahlen in unserer Datenbank verknüpfen. Dazu berechnen wir gleich noch die Differenz zwischen der Centipawn-Bewertung für den besten Zug (aus der vorherigen Zeile) und dem Centipawn-Wert für den real ausgeführten Zug.
SQL-Code
select
t.fen, t.half_move_num , t.move_white, t.move_black, t.best_move_uci, t.centipawn, t.centipawn_prv, (t.centipawn_prv - t.centipawn) cp_diff, t.accuracy
from
(
select
p.fen,
p.half_move_num ,
p.move_white ,
p.move_black ,
pa.best_move_uci ,
pa.centipawn ,
lag(pa.centipawn) over (
order by p.game_id,
p.half_move_num ) as centipawn_prv,
dp.accuracy
from
chess.position p
join chess.position_analysis as pa on
p.id = pa.position_id
left outer join chess.da_position as dp on
dp.position_id = pa.position_id
where
p.game_id = 2124959
order by
p.game_id,
p.half_move_num ) t;In der Spalte „cp_diff“ unten im Bild finden sich die Ausgangswerte zur Berechnung der ACPL-Kennzahlen.
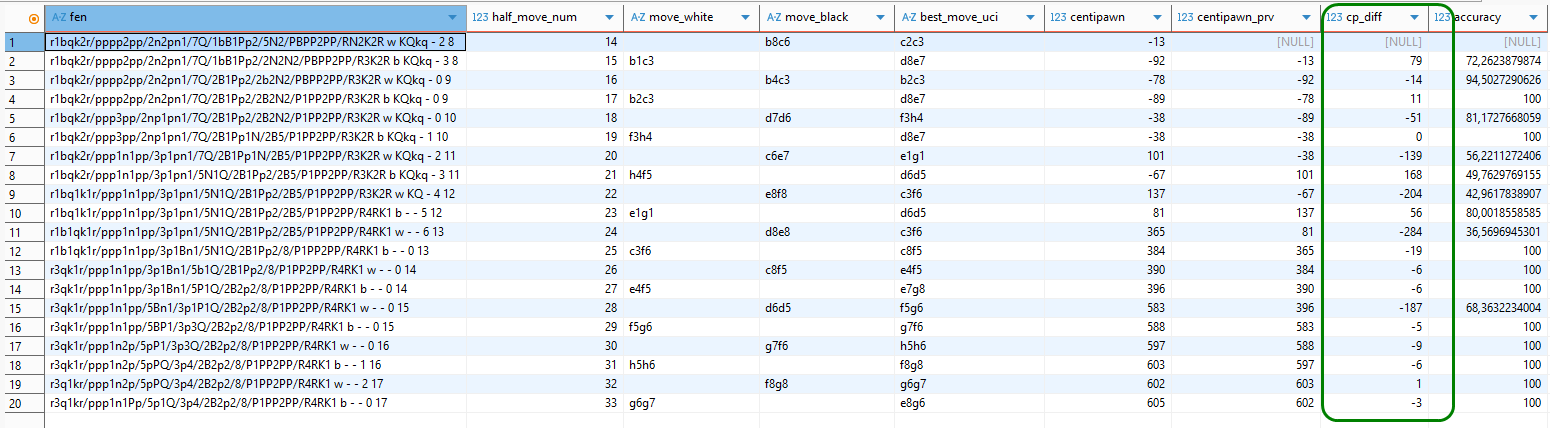
Im Bild oben haben wir der Übersichtlichkeit halber der centipawn-Bewertung der betreffenden Zeile bzw. Schachposition (in Spalte fen) die Centipawn-Bewertung der Ausgangsposition (aus der Zeile darüber) beigeordnet (Spalte centipawn_prv). Die Werte in der Spalte cp_diff ergeben sich nun einfach aus der Differenz centipawn_prv – centipawn.
Sehen wir uns die Werte von cp_diff genauer an. Zunächst stellen wir fest, dass in der allerersten Zeile der Wert dafür fehlt. Die Ursache liegt auf der Hand – für die erste Zeile fehlt der Vorgängerwert und damit die Berechnungsgrundlage. Das ist ok.
In der zweiten Zeile zog Weiß den suboptimalen Zug Sb1-c3, wodurch die centipawn-Bewertung von -13 (also einem marginalen Vorteil von Schwarz) auf -92 (fast einen ganzen Bauern) absackte. Dies manifestiert sich absolut in einem Verlustwert von 79 centipawn in der cp_diff-Spalte und lässt sich gleichfalls am accuracy-Wert von nur ca. 72% ablesen. Auch dieses Ergebnis erscheint plausibel.
In der dritten Zeile zog Schwarz Lb4-c3, statt des empfohlenen Dd8-e7, woraus sich eine Differenz von -14 ergibt. Dass hier eine negative Zahl entsteht, erscheint auf den ersten Blick widersinnig, da wir sie ja als Verlust in Hinblick auf den optimalen centipawn-Wert interpretieren wollen. Dabei zu berücksichtigen ist allerdings, dass die centipawn-Bewertung bewusst aus der Sicht von Weiß definiert wurde. Ein negativer Verlust bedeutet daher einen Gewinn für Weiß und das wiederum einen Wertverlust für Schwarz.
Wir berechnen daher eine Kennzahl cpl („centipawn loss“) aus dem Differenzwert, indem wir zusätzlich das Vorzeichen umkehren, falls Schwarz am Zug war. Warum wir stattdessen nicht einfach den Absolutwert heranziehen, sehen wir gleich.
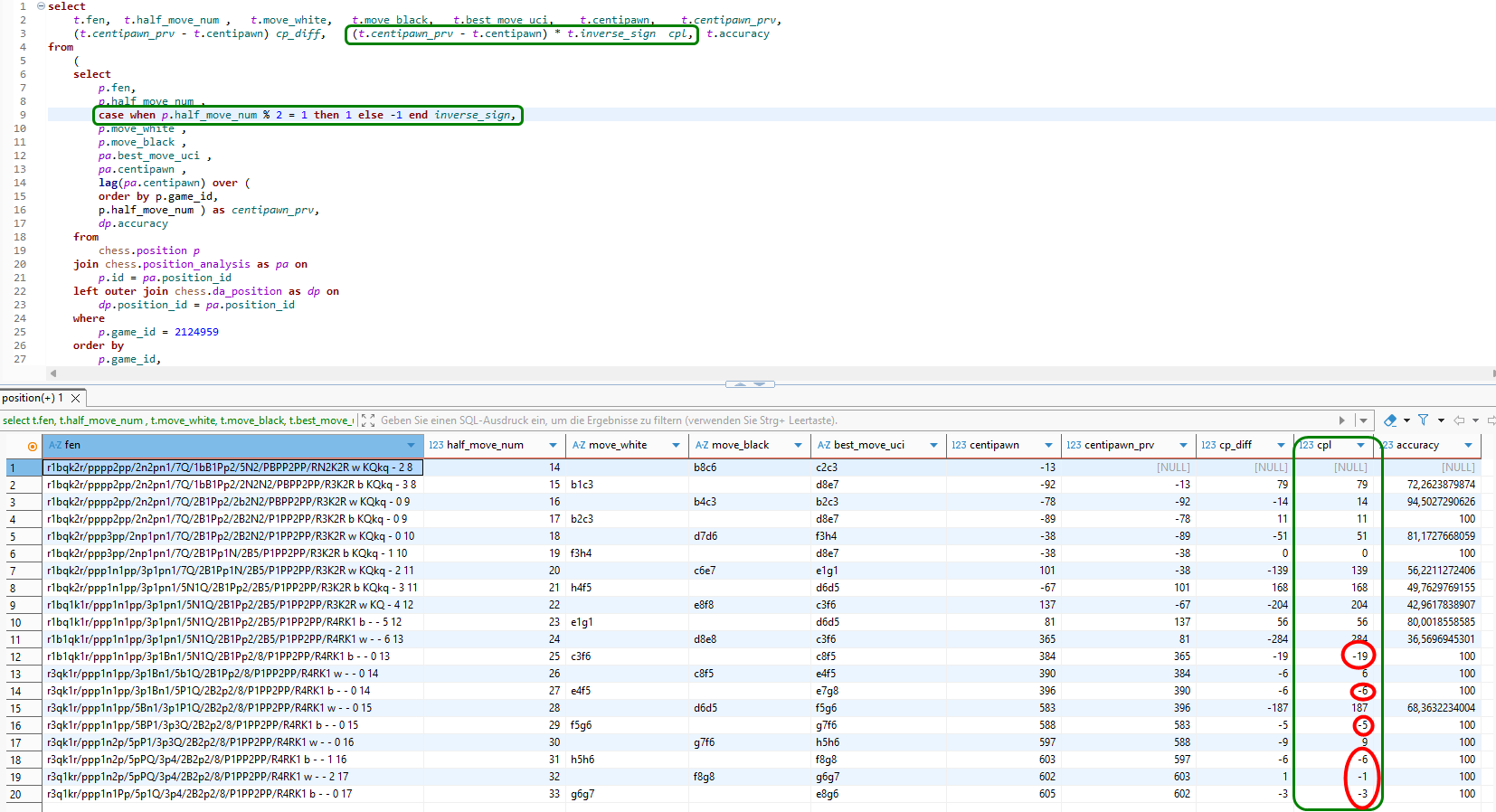
Wir hätten nun erwartet, dass die Verlustwerte in der neuen Spalte cpl alle positiv oder 0 (im Falle von 100% accuracy) sind. Doch wie kann es sein, dass in der Spalte cpl Werte ungleich 0 auch dann auftauchen, wenn der vorgeschlagene optimale Schachzug tatsächlich ausgeführt wurde?!
Betrachten wir zum Beispiel gleich die vierte Zeile. Es wurde genau der vorgeschlagene Zug 9) Lb2-c3 ausgeführt und trotzdem entstand ein centipawn-Verlust von 11!
Nun, das ist zu erklären. In der Position nach 9) Lb2-c3 kann Stockfish erstens auf die vorherige Analyse aufbauen und zweitens diese nun um mindestens einen Halbzug vertiefen. Dadurch kann es zu einem abweichenden Resultat bei der Bewertung kommen. Und solange das Schachprogramm keine zwingende Variante zur Mattsetzung gefunden hat, sind alle Bewertungsergebnisse stets mit dem Makel der Unvollkommenheit behaftet!
Wie wollen wir also mit dieser Situation umgehen? Wenn wir den cpl-Wert nun umdefinieren, dass auch negative Verluste möglich wären, würde das bedeuten, dass wir Züge besser als den „optimalen“ Zug einstufen müssten. Das passte dann nicht mehr zur accuracy oder man müsste dafür Werte größer als 100% zulassen und neu berechnen.
Dadurch entstünde eine kaum noch zu durchschauende Komplexität und Intransparenz, so dass wir lieber die näherliegende und leicht verständliche Herangehensweise vorziehen, den cpl-Wert immer dann auf 0 zu setzen, wenn die accuracy 100% beträgt.
Bevor wir dies umsetzen, müssen wir eine weitere Anomalie beheben. Angenommen, Weiß kann seinen Gegner in 5 Zügen matt setzen. Definitionsgemäß haben wir die centipawn-Bewertung in dieser Situation auf den exorbitant hohen Wert 32000 gesetzt. Wenn nun Weiß stattdessen einen anderen Zug wählt, der immer noch zu einer total gewonnenen Position für ihn führt mit z.B. einer centipawn-Bewertung von 2000, dann wäre der cpl-Wert für diesen Zug 30000, was sich auf den Durchschnittswert ACPL verheerend auswirken würde. Damit wir diese fatalen Ausschläge erkennen und beheben können, betrachten wir bei der cpl-Berechnung zusätzlich die Kennzahl accuracy.
Liegt diese bei 99% oder höher, setzen wir den cpl-Wert standardmäßig auf 0.
In diesem Zusammenhang trennen wir den cpl-Wert gleich noch auf in cpl_white und cpl_black und passen unsere SQL-Abfrage entsprechend an.
SQL-Code
select
t.fen,
t.half_move_num ,
t.move_white,
t.move_black,
t.best_move_uci,
t.centipawn,
case
when t.half_move_num % 2 = 0 then null
else case
when t.accuracy >= 99 then 0
else (t.centipawn_prv - t.centipawn) * t.inverse_sign
end
end cpl_white,
case
when t.half_move_num % 2 = 1 then null
else case
when t.accuracy >= 99 then 0
else (t.centipawn_prv - t.centipawn) * t.inverse_sign
end
end cpl_black,
t.accuracy
from
(
select
p.fen,
p.half_move_num ,
case
when p.half_move_num % 2 = 1 then 1
else -1
end inverse_sign,
p.move_white ,
p.move_black ,
pa.best_move_uci ,
pa.centipawn ,
lag(pa.centipawn) over (
order by
p.game_id,
p.half_move_num ) as centipawn_prv,
dp.accuracy
from
chess.position p
join chess.position_analysis as pa on
p.id = pa.position_id
left outer join chess.da_position as dp on
dp.position_id = pa.position_id
where
p.game_id = 2124959
order by
p.game_id,
p.half_move_num ) t;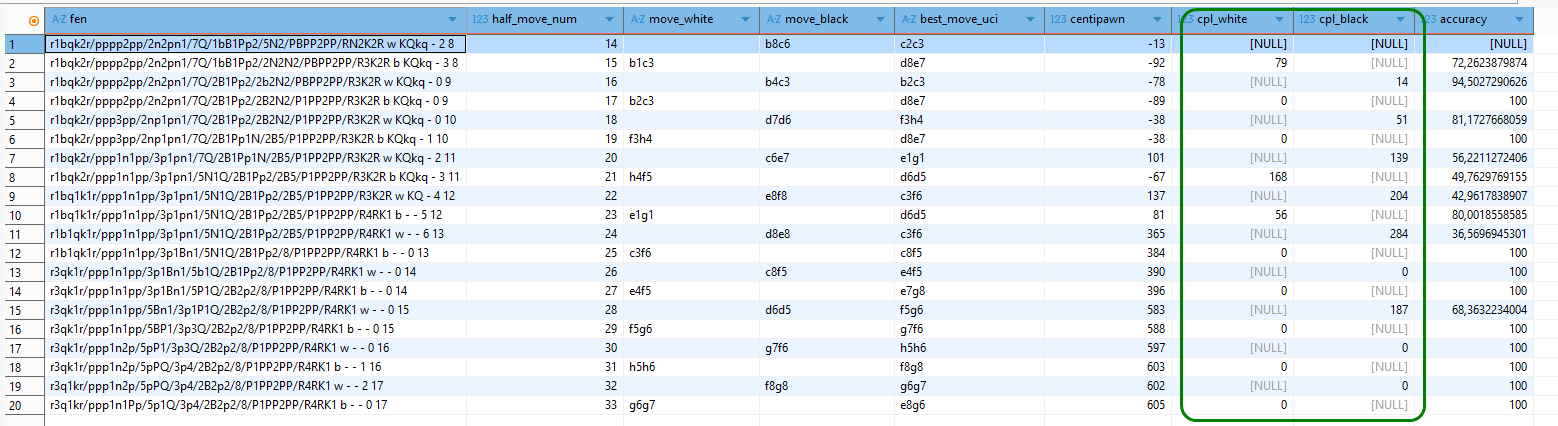
STDCPL
ACPL („average centipawn loss“) ist wie der Name bereits ausdrückt ein Durchschnittswert. Dabei ist ein möglichst niedriger Wert zwar gut, aber allein nicht unbedingt aussagekräftig. Denn die beste Gegenwehr nutzt einem Spieler wenig, wenn er z.B. einmal einen Verlustzug ausgeführt hat, den der Gegenspieler auszunutzen versteht. Selbst wenn der Spieler von dort an jeden Zug mit einer Genauigkeit von 100% spielt, muss er die Partie verlieren. Um diesen Sachverhalt sichtbar zu machen, benutzen wir die Standardabweichung der cpl-Werte als statistisches Maß hierfür. Je kleiner dieser Wert ist, desto geringer ist die Wahrscheinlichkeit für einen groben Schnitzer.
Für die Berechnung von ACPL und der neuen Kennzahl STDCPL ( „Standard Deviation Centipawn Loss“) benutzen wir die eingebauten Funktionen AVG() und STDDEV_SAMP() von MariaDB.
SQL-Code
select
avg(cpl_white) acpl_white,
avg(cpl_black) acpl_black,
stddev_samp(cpl_white) stdcpl_white,
stddev_samp(cpl_black) stdcpl_black,
avg(case when cpl_white is not null then accuracy else null end) accuracy_avg_white,
avg(case when cpl_black is not null then accuracy else null end) accuracy_avg_black
from
(
select
t.fen,
t.half_move_num ,
t.move_white,
t.move_black,
t.best_move_uci,
t.centipawn,
case
when t.half_move_num % 2 = 0 then null
else case
when t.accuracy = 100 then 0
else (t.centipawn_prv - t.centipawn) * t.inverse_sign
end
end cpl_white,
case
when t.half_move_num % 2 = 1 then null
else case
when t.accuracy = 100 then 0
else (t.centipawn_prv - t.centipawn) * t.inverse_sign
end
end cpl_black,
t.accuracy
from
(
select
p.fen,
p.half_move_num ,
case
when p.half_move_num % 2 = 1 then 1
else -1
end inverse_sign,
p.move_white ,
p.move_black ,
pa.best_move_uci ,
pa.centipawn ,
lag(pa.centipawn) over (
order by
p.game_id,
p.half_move_num ) as centipawn_prv,
dp.accuracy
from
chess.position p
join chess.position_analysis as pa on
p.id = pa.position_id
left outer join chess.da_position as dp on
dp.position_id = pa.position_id
where
p.game_id = 2124959
order by
p.game_id,
p.half_move_num ) t ) t2;Im obigen Match „Goliath vs David“ entsprechen die resultierenden ACPL– und STDCPL-Werte voll und ganz unseren Erwartungen.

Wenn wir die Korrektheit unserer Berechnungen für obige Partie überprüfen wollen, indem wir sie z.B. von lichess.org analysieren lassen, erhalten wir allerdings abweichende Ergebnisse, die sich nicht durch Rechenungenauigkeiten erklären lassen.
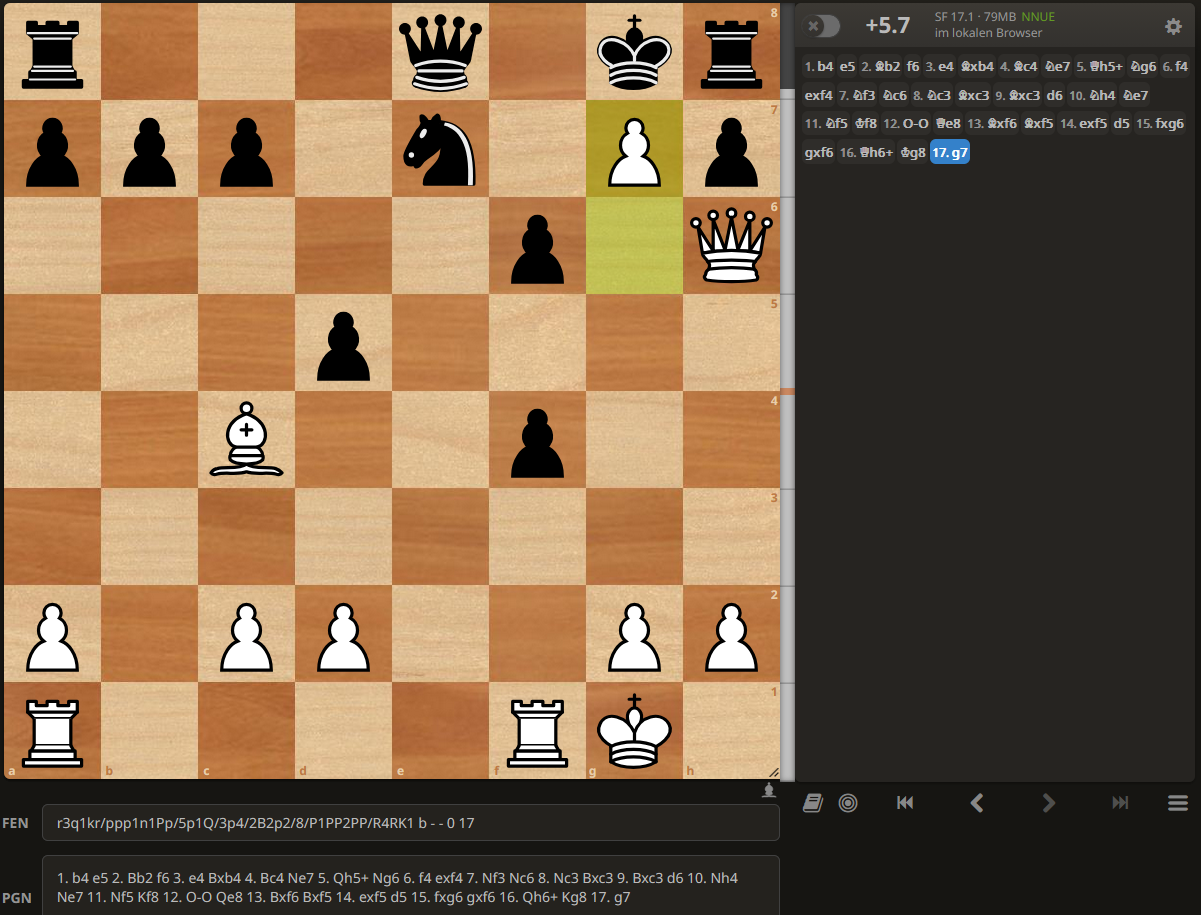
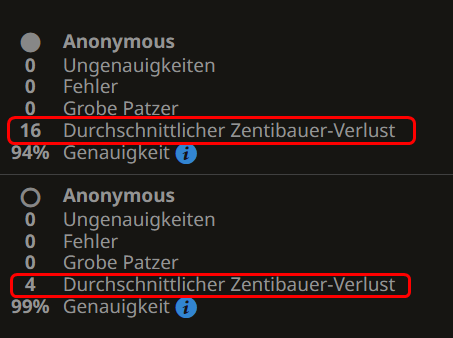
Haben wir also falsch gerechnet? Kurze Antwort: Nein, aber wir verwenden eine andere Berechnungsgrundlage.
Wenn wir uns nochmal die obigen Daten ansehen, machen wir uns wieder klar, dass wir die bekannten Eröffnungszüge aus den Theoriebüchern bewusst gar nicht bewerten wollten!
Dieser doch gravierende Unterschied zwischen den ACPL-Werten von lichess.org und unseren (4 vs 30 bzw. 16 vs 97) kennzeichnet den überragenden Einfluss von Eröffnungswissen im moderen Schachspiel. Doch was uns im Spielervergleich wirklich interessiert, ist Schachkönnen ohne Zuhilfenahme von dicken Eröffnungstheoriebüchern und vorbereiteten Varianten, evtl. ermittelt durch lange Computer-Analysen!
ACCURACY
Es steht zu vermuten, dass auch die Genauigkeitsrate sinken wird, wenn wir bekannte Eröffnungszüge unberücksichtigt lassen. Wir rechnen das kurz nach, indem wir unser SQL etwas erweitern.
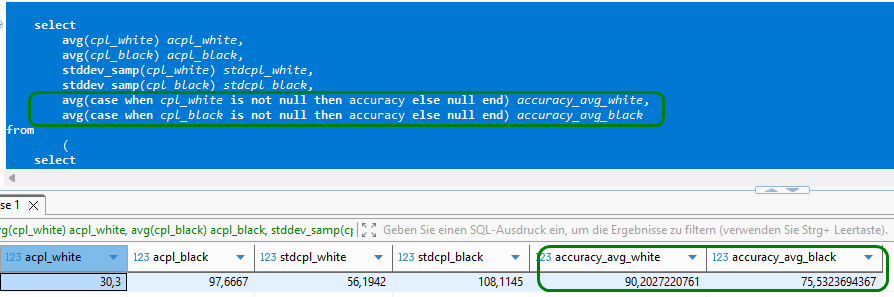
Wie fast nicht anders zu erwarten, sinken die Genauigkeits-Werte signifikant im Vergleich zur vollständigen Partie inklusive aller Züge aus dem Eröffnungsbuch.
Eine Anomalie
Folgende Situation vergleichbar zu dem obigen Fall ist denkbar: die Schachengine schlägt einen Zug vor mit einem errechneten centipawn-Wert x. Der Zugführende spielt aber einen alternativen Zug und die daraus resultierende Stellung wird mit einem centipawn-Wert y belohnt, wobei x < y !
Demnach korrigiert die engine nachträglich ihren eigenen Vorschlag. Tatsächlich finden wir in unseren Analysedaten Tausende solcher Fälle. Doch glücklicherweise werden auch diese Züge stets mit einer accuracy von 100% belohnt!
Stellungs-Komplexität
Wir hatten im vorigen Kapitel ein relativ aufwändiges Verfahren zur Beurteilung der Stellungskomplexität kurz vorgestellt und wegen dieses Aufwandes auch gleich wieder verworfen.
Wünschenswert wäre daher ein einfacher Indikator, mit dessen Hilfe wir beurteilen könnten, ob eine vorliegende Position kompliziert ist, wo spielbare Züge schwerer zu finden sind als in einer Position, wo der nächste Zug auf der Hand liegt bzw. sogar erzwungen ist. Dann ließe sich die Qualität von einzelnen Zügen gewichten, indem man gute Züge in einer schwierigen/einfachenPosition mit einem Bonus bzw. Malus versieht. Andersherum ließen sich schlechte Züge in schwierigen Positionen leichter verzeihen als in einfachen Positionen.
Eine naheliegender Kandidat für einen solchen Komplexitäts-Indikator wäre der Rechenaufwand, welchen Stockfish für die Stellungsanalyse erbringt. Dazu haben wir bereits die Kennzahlen nodes, depth, seldepth und time_sec für jeden Zug in der Tabelle position_analysis mitgeführt.
Zu diesem Zweck haben wir mit nodes etwas experimentiert, indem wir mit Hilfe von Erwartungswert und Standardabweichung die drei Klassen (-1, 0, 1 für „leicht“, „normal“ und „schwierig“) bildeten und einige bekannte Schachpartien daraufhin untersuchten.
SQL-Code
select t3.half_move_num,
t3.move_white ,t3.move_black ,
t3.nodes_white,
#t3.avg_nodes_white ,
#t3.stdev_nodes_white ,
case when t3.nodes_white > t3.avg_nodes_white + t3.stdev_nodes_white then 1
when t3.nodes_white < t3.avg_nodes_white - t3.stdev_nodes_white then -1
else 0
end complexity_white,
t3.nodes_black,
#t3.avg_nodes_black,
#t3.stdev_nodes_black,
case when t3.nodes_black > t3.avg_nodes_black + t3.stdev_nodes_black then 1
when t3.nodes_black < t3.avg_nodes_black - t3.stdev_nodes_black then -1
else 0
end complexity_black
from (
select
t2.half_move_num,
t2.move_white ,t2.move_black ,
t2.nodes_white,
avg(t2.nodes_white) over () as avg_nodes_white ,
stddev_samp(t2.nodes_white) over () as stdev_nodes_white ,
t2.nodes_black,
avg(t2.nodes_black) over () as avg_nodes_black,
stddev_samp(t2.nodes_black) over () as stdev_nodes_black
from
(
select
t.half_move_num ,
t.move_white ,t.move_black ,
case
when t.half_move_num % 2 = 1 and t.accuracy is not null then t.nodes
else null
end nodes_white,
case
when t.half_move_num % 2 = 0 and t.accuracy is not null then t.nodes
else null
end nodes_black
from
(
select
p.half_move_num ,
p.move_white ,p.move_black ,
pa.nodes,
dp.accuracy
from
chess.position p
join chess.position_analysis as pa on
p.id = pa.position_id
left outer join chess.da_position as dp on
dp.position_id = pa.position_id
where
p.game_id = 10823787 # Schach-WM 1972: Partie 13, Spasski - Fischer
) t)t2)t3
order by
t3.half_move_num;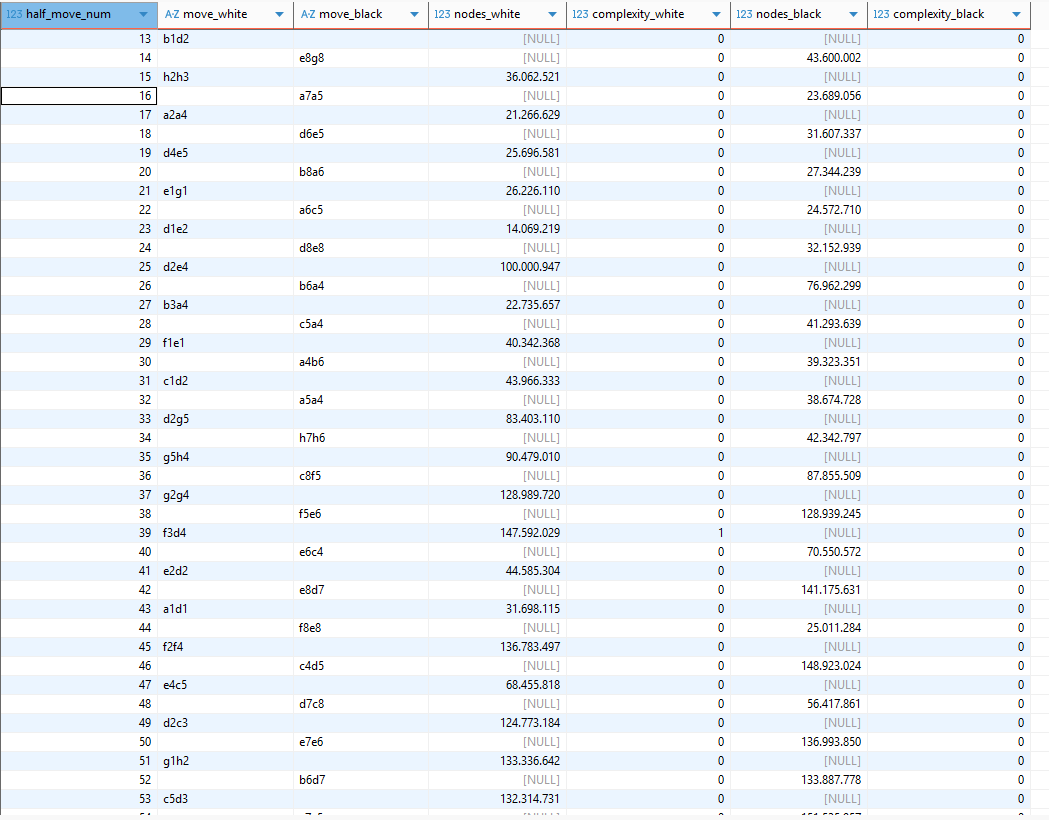
Nach eingehender Prüfung des Ergebnisses müssen wir allerdings feststellen, dass kein signifikanter Zusammenhang zwischen Rechenaufwand (in nodes) und tatsächlicher Stellungskomplexität erkennbar ist. Somit verwerfen wir diesen Ansatz wieder.
Sharpness
Wie bereits ausgeführt, lässt sich anhand der WDL-Bewertung von Stockfish diese Kennzahl schwerlich ablesen, so dass wir vorerst von einer weiteren Verdichtung auf Partieebene absehen.
weitere Aggregationen
Abschließend zählen wir für jede Partie die Anzahl Halbzüge sowie diejenigen Züge von Weiß und Schwarz, die wir als ‚BLUNDER‘, ‚MISTAKE‘, ‚ENGINE‘ und ‚NORMAL‘ (für die übrigen Züge) eingestuft hatten. Wir begnügen uns vorerst mit diesen Partie-Kennzahlen und starten mit der Implementierung.
Datenmodell-Erweiterung
Wie bereits skizziert, erstellen wir für die Partie-Kennzahlen eine separate Tabelle da_game, die wir mit der Tabelle game über eine entsprechende Fremdschlüssel-Beziehung verknüpfen.
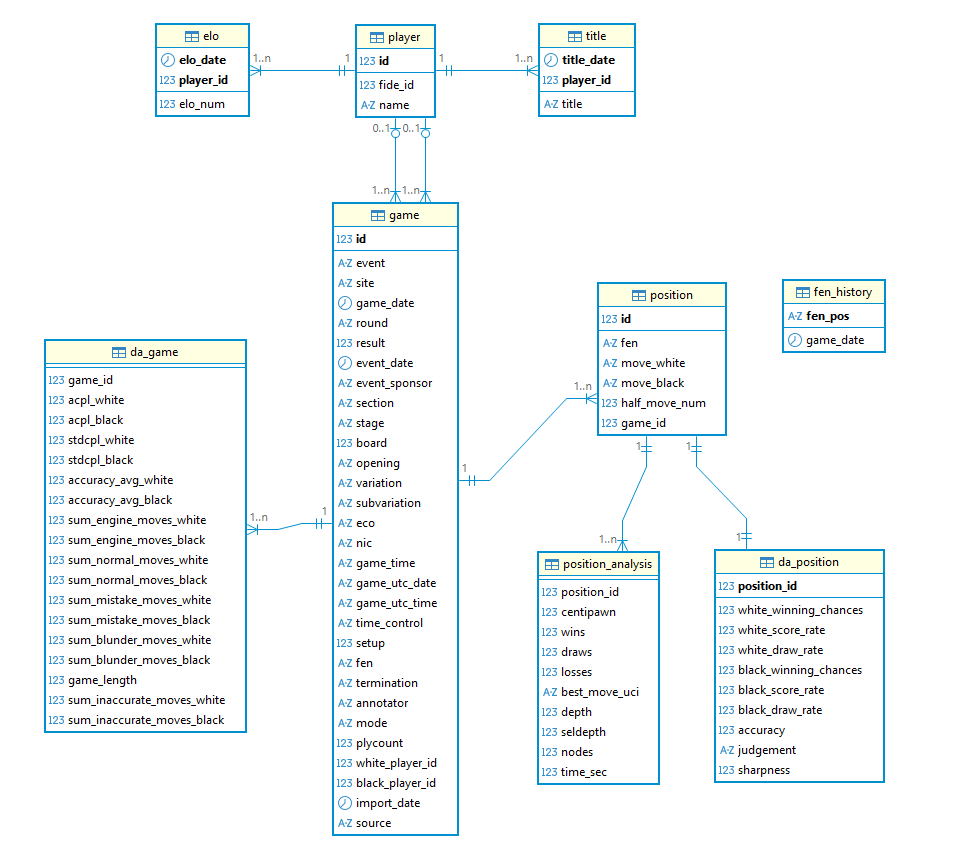
Package-Erweiterung
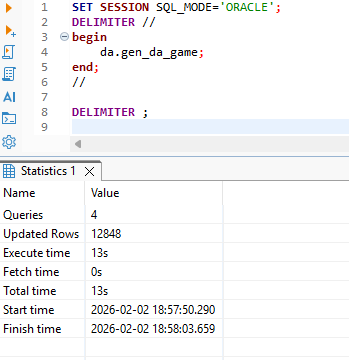
Zum Befüllen unserer neuen Tabelle erweitern wir das vorhandene PL/SQL-Package da in der Datenbank. Die neue Prozedur gen_da_game löscht zunächst die Zieltabelle und iteriert danach über alle analysierten Partien, um für jede einzelne einen entsprechenden Datensatz in der Tabelle da_game einzutragen.
Die Ausführungszeit der Prozedur beträgt lediglich 13 Sekunden.
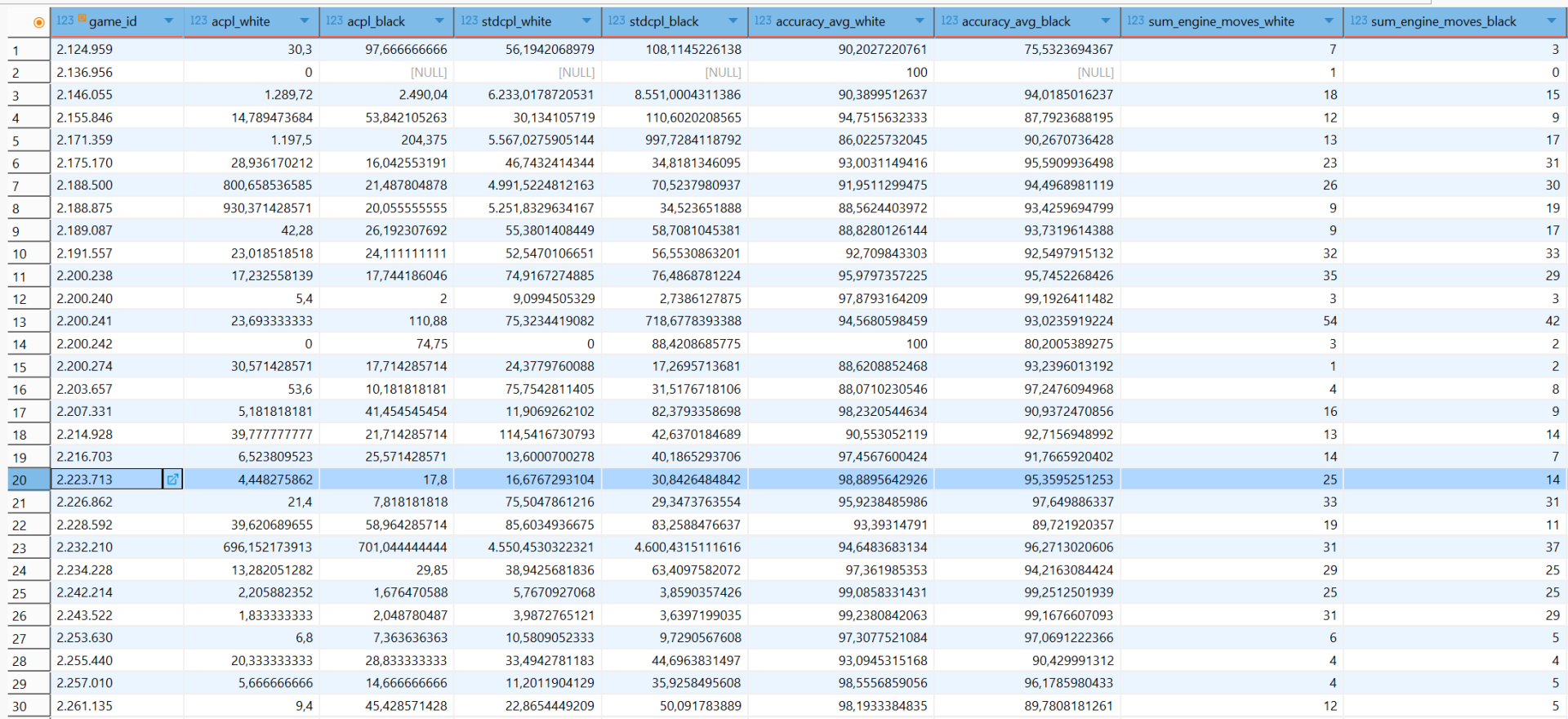
Mit einer kurzen Sichtkontrolle auf die entstandenen Daten wollen wir dieses Kapitel beenden.
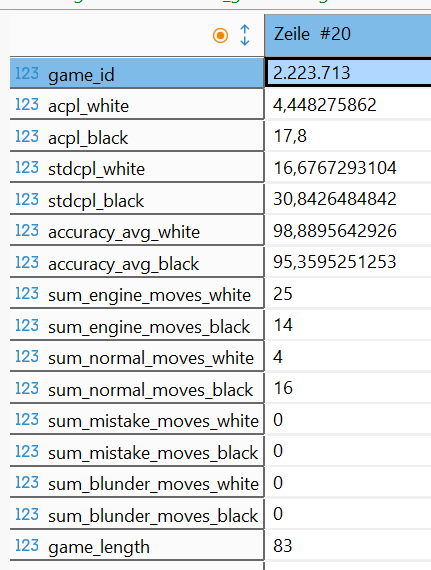
Im nächsten Kapitel beschäftigen wir uns mit der Visualisierung unserer gewonnenen Daten.