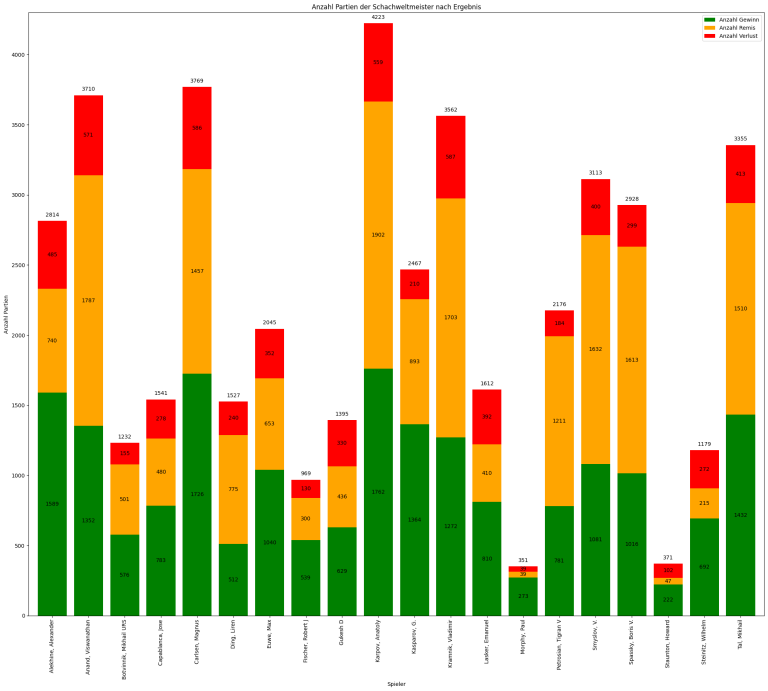
Wir würden gerne zumindest die Partien aller Schachweltmeister einer Analyse unterziehen. Wir beginnen unser Unterfangen mit den 1179 Partien des ersten Weltmeisters Wilhelm Steinitz, die in unserer Datenbank gespeichert sind. Spätestens jetzt taucht die Frage nach der Gesamt-Laufzeit und damit der Machbarkeit unseres Vorhabens insgesamt auf.
Nachdem wir das Programm gestartet haben, beginnen kurz darauf die CPU-Lüfter merklich laut zu rauschen – ein gutes Zeichen, dass wir die Performance optimal getuned haben. Der Rechner scheint die Dauerlast gut auszuhalten und so werfen wir nach etlichen Stunden einen Blick auf die Zwischenergebnisse.
Wir schauen in unsere Logdatei und sehen, dass unser Analyseprogramm bisher ca. 13,5 Stunden lief.

Danach prüfen wir den Umfang der soweit erzielten Ergebnisse in der Datenbank, nämlich die Anzahl der vollständig analysierten Partien.
SQL-Code
select
g.id,count(*)
from
game g
join player pw on
g.white_player_id = pw.id
join player pb on
g.black_player_id = pb.id
join position p on
(g.id = p.game_id)
join position_analysis pa on
(p.id = pa.position_id)
where
pw.id = 4375261
or pb.id = 4375261
group by g.id;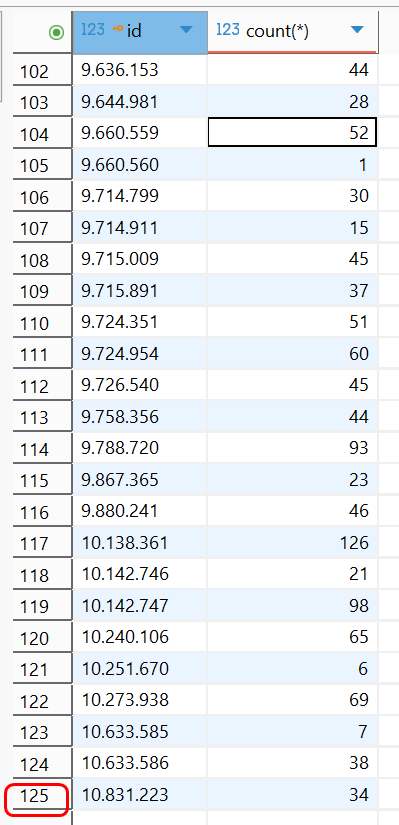
Damit können wir die Gesamtlaufzeit für alle zu analysierenden Partien abschätzen (13,5 / 125 * 1179). Dies entspricht einer Laufzeit von ca. 5,3 Tagen!

Das mag gerade noch akzeptabel erscheinen, aber wenn man berücksichtigt, dass die meisten Groß- und Weltmeister der jüngeren Vergangenheit z.T. über 4000 Partien vorzuweisen haben, wird schnell klar, dass eine umfassende Analyse dieser Spieler mit der aktuellen Konstellation viele Monate in Anspruch nehmen würde.
Diesen Aufwand können und wollen wir derzeit nicht leisten und fragen uns stattdessen, ob nicht etwa eine repräsentative Stichprobe für unsere Zwecke genügen könnte. Wenn wir beispielsweise pro Schachweltmeister über dessen gesamte Schaffensperiode hinweg zufällig jeweils 350 Partien analysieren, würde sich der zeitliche Analyseaufwand pro Spieler auf ca. 2 Tage drastisch verkürzen. Die Zahl 350 wird hier bewusst gewählt, da sie der kleinsten Anzahl Partien entspricht, die für einen (wenn auch inoffiziellen) Weltmeister, in diesem Fall Paul Morphy, in unserer Datenbank aufgezeichnet sind.
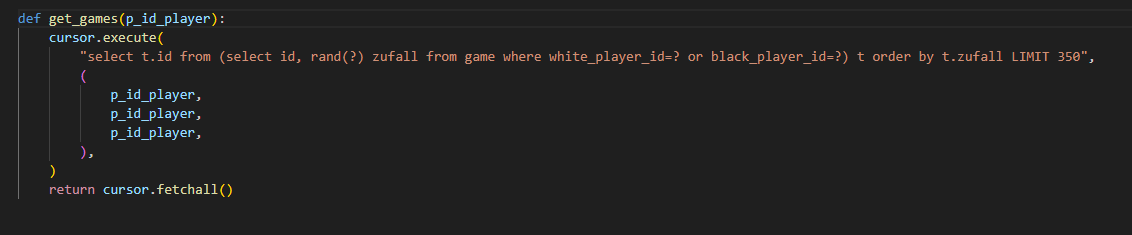
Technisch ist diese Anforderung leicht zu realisieren. Dazu modifizieren wir die bestehende SQL-Abfrage für die Ermittlung der zu analysierenden Partien, indem wir pro Zeile einen Zufallswert generieren, diese Liste danach (zufällig) sortieren und davon die ersten 350 Partien verwenden. Damit die Wiederaufsetzbarkeit unseres Programms gewährleistet bleibt, verwenden wir für die rand()-Funktion von MariaDB, die diesen Zufallswert generiert, einen sogenannten SEED, der dafür sorgt, dass die erzeugten Zufallszahlen bei Wiederholung des Programms mit dem selben SEED exakt reproduziert werden. Als konkreten Wert für SEED nehmen wir die jeweilige Player ID. Wir könnten stattdessen auch eine beliebige Zahlenkonstante verwenden.
Wir löschen alle bisherigen Analyse-Ergebniss aus der Datenbank und starten unser Programm erneut.

Nach ziemlich genau 2 Tagen ist das Programm beendet und wir können das Ergebnis prüfen.
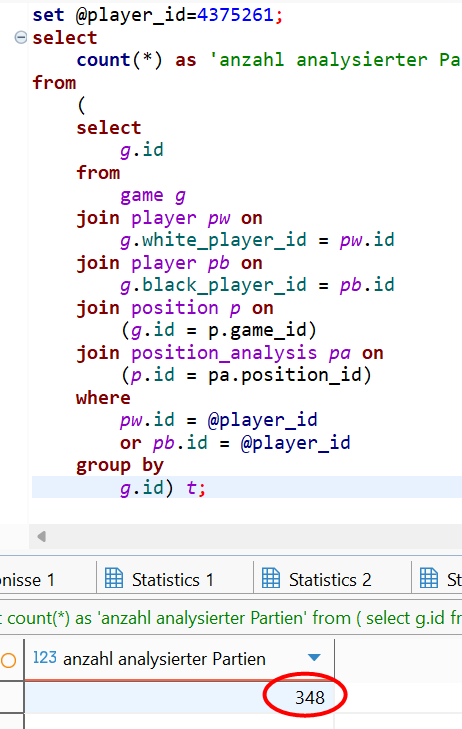
Was ist da passiert? Wir überprüfen unser Logfile auf Fehlermeldungen. Tatsächlich finden wir zwei ERROR-Meldungen.
...
2025-11-18 14:43:45 ERROR Error analyzing game 9867365: 'pv'
...
2025-11-18 17:16:56 ERROR Error analyzing game 9523001: 'pv'
...Der Fehlertext ‚pv‘ ist allerdings nicht sehr erhellend. Zum Glück können wir die betreffenden Partien anhand ihrer ID in der Datenbank rasch finden und überprüfen.
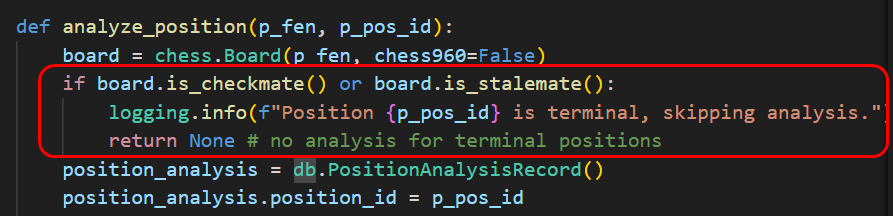
Auf den ersten Blick sind beide Partien valide und alle Züge nachspielbar. Bei näherer Betrachtung fällt allerdings auf, dass beide Partien mit Mattsetzung enden. Da wir sämtliche Züge bzw. die daraus resultierenden Positionen einer Partie und damit auch eventuell entstehende Mattpositionen wie hier analysieren, ergibt sich für die chess engine ein Problem: hier gibt es nichts mehr zu analysieren! Das Gleiche gilt für Patt-Stellungen – es existieren per Definition keine legalen Züge mehr. Das Schachprogramm beschwert sich zu Recht.
Und wie nicht anders zu erwarten bietet die python-chess Bibliothek genau die Funktionalität, um diese Situationen zu erkennen. Damit korrigieren wir in unser Programm, um die Analyse solcher Stellungen zu unterdrücken.
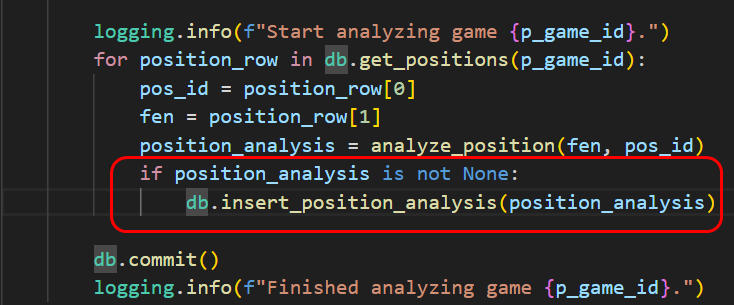
Wir müssen unser Programm lediglich nochmals starten. Die bereits vorhandenen Ergebnisse werden automatisch erkannt und es werden dafür keine erneuten Analysen durchgeführt. Nach einigen Minuten sind auch die beiden fehlenden Partien nachanalysiert.
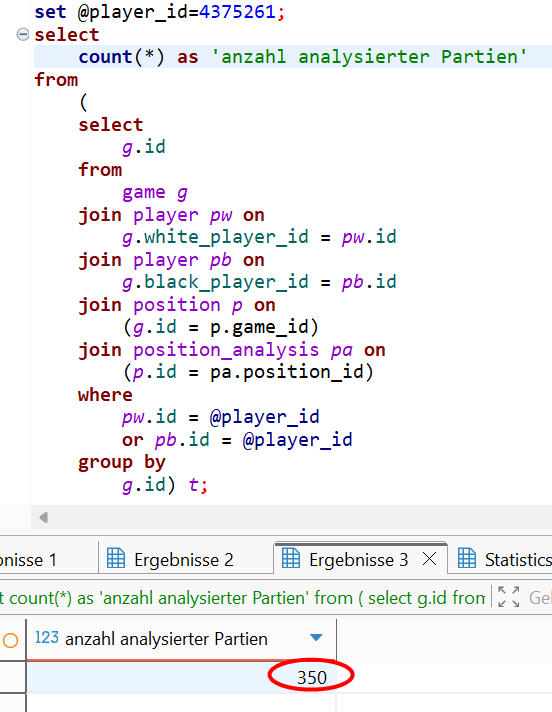
Vorausschickend sei aber erwähnt, dass sich die Anzahl analysierter Partien pro Spieler durch Seiteneffekte weiter erhöhen kann! Um das zu erklären, bleiben wir beim Beispiel der gerade analysierten 350 Partien von Wilhelm Steinitz. Wenn wir nun nachfolgend die Partien von Zeitgenossen wie den späteren Weltmeistern Lasker oder Capablanca analysieren, so kann es vorkommen, dass in der zufälligen Auswahl dieser Partien solche enthalten sind, in denen Steinitz der Gegner war und die aber nicht in der vorherigen Zufallsauswahl für Steinitz vorhanden waren. Genauso kann es umgekehrt vorkommen, dass eine bereits analysierte Partie per Zufall für einen anderen Spieler nochmals zur Analyse bestimmt wird. Die zweite Analyse wird dabei zwar übersprungen und es führt auch nicht dazu, dass für einen Spieler weniger als 350 Partien analysiert werden. Doch ergeben sich im Endeffekt gewisse Schwankungen bei der Anzahl der effektiv analysierten Partien pro Spieler. Dies stellt kein ernsthaftes Manko dar, ist aber gut zu wissen.
Datenqualität
Wir wollen uns einen Überblick darüber verschaffen, wie sich das Verhältnis von Anzahl gespielter Halbzüge unserer analysierten Partien zur Anzahl neuartiger und damit analysierter Halbzüge gestaltet. Wir untersuchen zunächst die Partien von Wilhelm Steinitz mit folgender SQL-Anweisung.
SQL-Code
select
g.id game_id,
count(*) anzahl_halbzuege,
sum(case when pa.position_id is null then 0 else 1 end) anzahl_analysierter_halbzuege
from
player p
join game g on
(g.black_player_id = p.id
or g.white_player_id = p.id)
join position po on
(po.game_id = g.id)
left outer join position_analysis pa on
(pa.position_id = po.id)
where
p.id = 4375261 # Steinitz
group by
g.id
having
sum(case when pa.position_id is null then 0 else 1 end) >0
order by
3,
2 ;Entsprechend sortiert liefert die Ergebnisliste eine merkwürdige Überraschung!
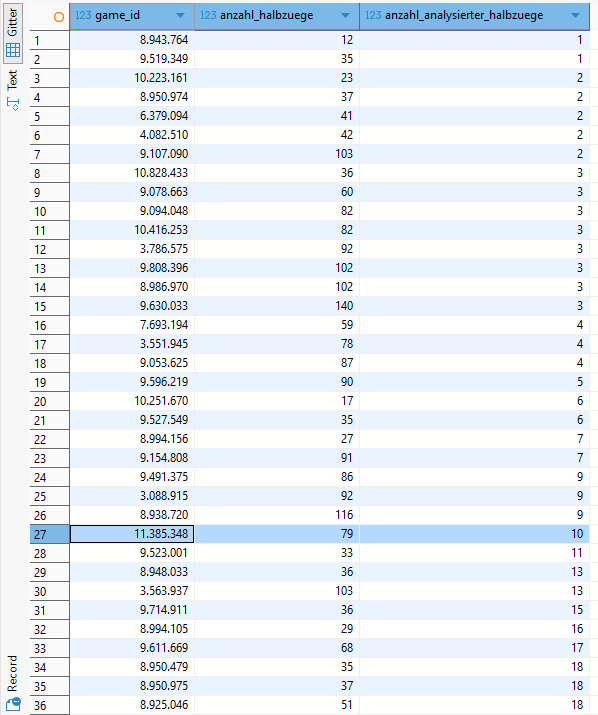
Dass bei einer Partie von 12 Halbzügen (in Zeile 1) nur ein einziger Zug analysiert wurde, erscheint noch verständlich, auch wenn eine solch kurze Partie sehr ungewöhnlich ist.
Dass aber z.B. von einer Partie mit 79 Halbzügen (Zeile 27) lediglich 10 analysiert wurden, macht uns stutzig. Das würde bedeuten, dass diese Partie 69 Halbzüge lang auf den Spuren einer vorangegangenen Partie gewandelt ist.
Das ist mehr als unwahrscheinlich!
Sehen wir uns dieses Beispiel daher genauer an.
SQL-Code
set @player_id=4375261 ; # Steinitz
set @game_id=11385348;
select
pw.name,
pb.name,
g.id game_id,
p.fen,
p.half_move_num ,
p.move_white ,
p.move_black ,
pa.best_move_uci ,
pa.centipawn ,
pa.wins ,
pa.draws ,
pa.losses,
da.*
from
game g
join player pw on
g.white_player_id = pw.id
join player pb on
g.black_player_id = pb.id
join position p on
(g.id = p.game_id)
left outer join position_analysis pa on
(p.id = pa.position_id)
left outer join da_position da on
(da.position_id = pa.position_id )
where
(pw.id = @player_id
or pb.id = @player_id)
and g.id = @game_id
order by
g.id,
p.half_move_num
;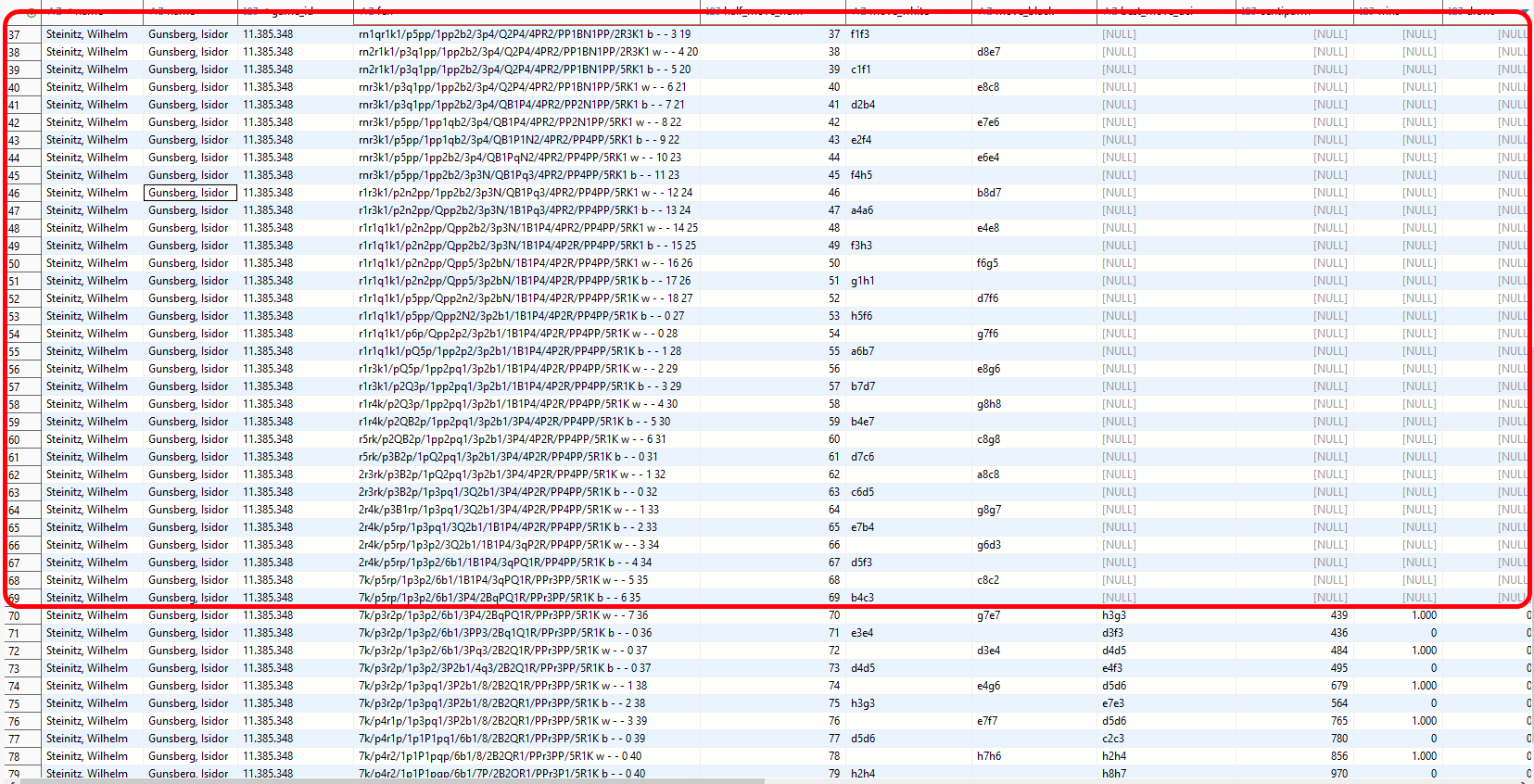
Betrachten wir die letzte nicht analysierte Stellung dieser Partie im 69. Halbzug.
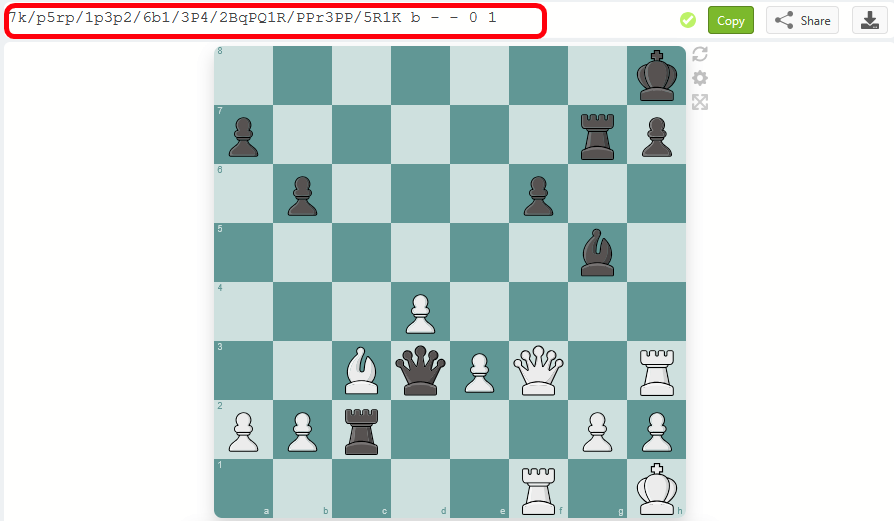
Wir sehen, dass es sich um ein weit fortgeschrittenes Spiel handelt, nahe einer Endspielposition. Wir suchen daher nach einem Vorgänger-Spiel in unserer Datenbank, in dem genau diese Stellung auf dem Brett stand. Dazu müssen wir die Tabelle mit sämtlichen Positionen aller Partien durchsuchen. Dabei interessieren uns die beiden letzten FEN-Felder „Halfmove clock“ und „Fullmove number“ wie schon bei der Analyse-Ausschluss-Prüfung nicht.
select
*
from
position p
where
p.fen like '7k/p5rp/1p3p2/6b1/3P4/2BqPQ1R/PPr3PP/5R1K b - -%';
Et voilà – da haben wir den Übeltäter! Es ist die Partie mit game.id = 11385347. Die andere (11385348) wurde von uns analysiert. Mehr erfahren wir aus den Partie-Daten.
select
id,
event,
site,
game_date,
round,
result,
white_player_id,
black_player_id,
import_date,
source
from
game
where
id in (11385348, 11385347);
Ganz offensichtlich handelt es sich hier um ein Duplikatsproblem, wahrscheinlich hervorgerufen durch den Partien-Import aus unterschiedlichen Quellen und einer unzureichenden nachträglichen Bereinigung.
Doch wie sollen wir mit dieser Situation umgehen? Um eine selbst gestrickte Duplikatsprüfung zu implementieren, fehlt uns die Zeit und der Antrieb. Unsere analysierte Datenbasis wird dadurch ja auch nicht fehlerhaft, sie ist ist lediglich in Teilen unvollständig. Trotzdem ist es mehr als unbefriedigend, Rückschlüsse aus halb analysierten Partien ziehen zu wollen. Da wir nicht den Aufwand treiben können, jedem Einzelfall konkret nachzugehen, suchen wir eine pragmatische Bereinigungs-Lösung, indem wir unzureichende Analysedaten nachträglich wieder verwerfen, sprich löschen. Aber was ist „unzureichend“?
Damit wir nicht nur auf eine Vermutung durch bloße Schätzung angewiesen sind, rechnen wir einfach, indem wir den Anteil analysierter Züge pro Partie betrachten und dabei Stichproben untersuchen.
SQL-Code
select
g.id game_id,
count(*) anzahl_halbzuege,
sum(case when pa.position_id is null then 0 else 1 end) anzahl_analysierter_halbzuege,
round(100 * sum(case when pa.position_id is null then 0 else 1 end) / count(*), 2) anteil_analysierter_halbzuege_proz
from
player p
join game g on
(g.black_player_id = p.id
or g.white_player_id = p.id)
join position po on
(po.game_id = g.id)
left outer join position_analysis pa on
(pa.position_id = po.id)
where
p.id = 4375261 # Steinitz
group by
g.id
having
sum(case when pa.position_id is null then 0 else 1 end) >0
order by
4;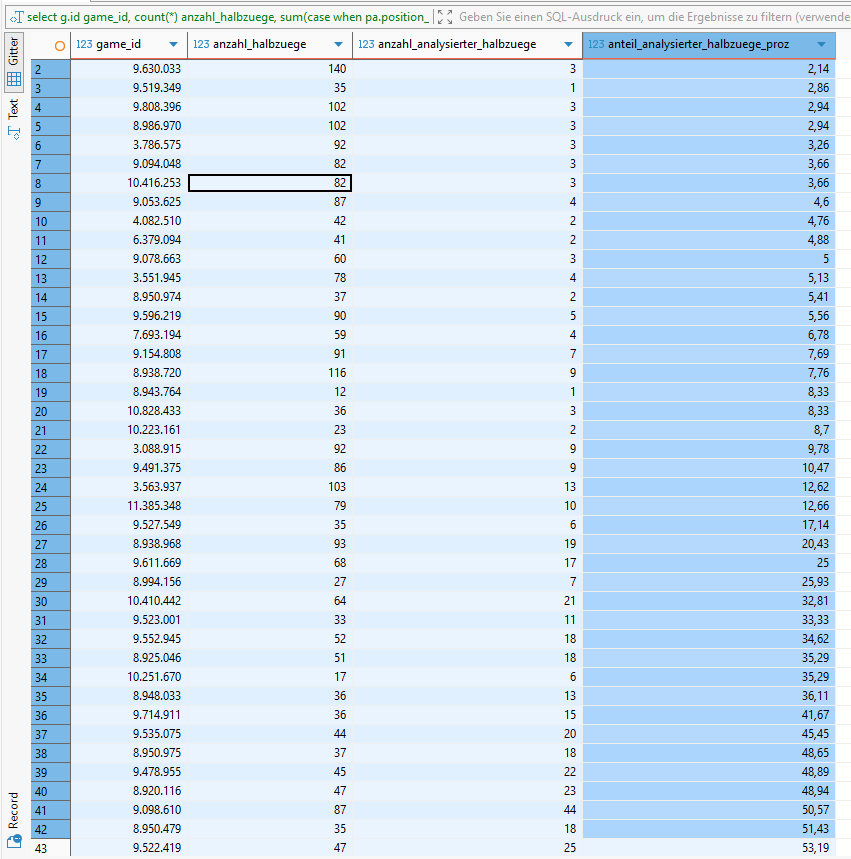
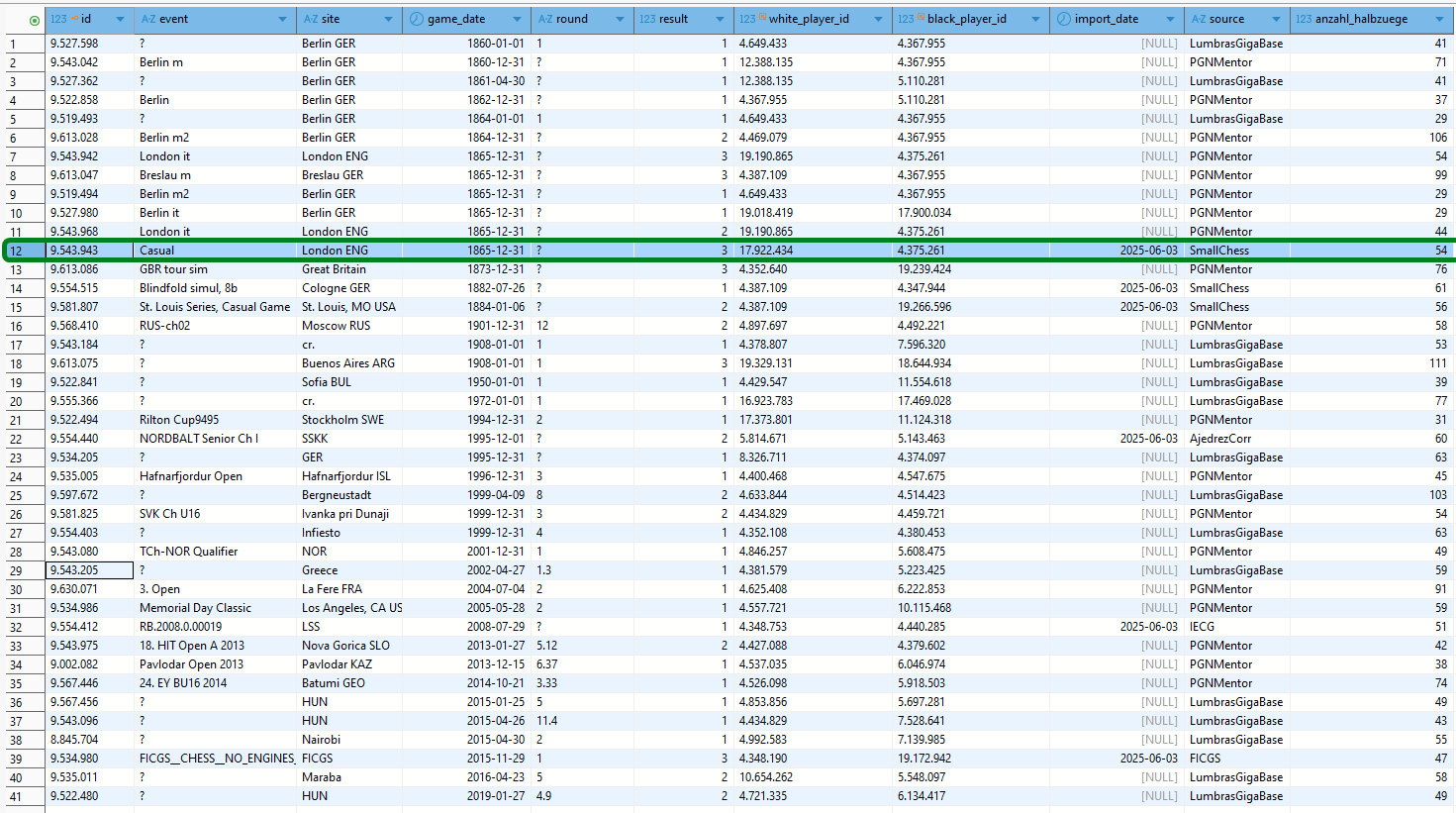
Wir sehen, dass von den 355 Steinitz-Partien 40 zu weniger als der Hälfte analysiert wurden. Partien, deren Analyse-Anteil im einstelligen Prozentbereich liegt, können wir auf jeden Fall ausschließen. Unsere Prüfungen in Zehnerschritten ab dem Schwellwert 30% zu beginnen, klingt zumindest nicht völlig unvernünftig. Wir werden dazu vier Fälle genauer untersuchen.
- Partie 10410442 (Analyseanteil: 32.81%)
- Partie 9714911 (Analyseanteil: 41.67%)
- Partie 9098610 (Analyseanteil: 50.57%)
- Partie 9543943 (Analyseanteil: 61.11%)
Wir müssen bei der Recherche dazu lediglich in den vorherigen SQL-Abfragen die Parameter austauschen.
1) Partie Wilhelm Steinitz – Henry Bird 31.12.1866
Wie zu vermuten war, handelt es sich auch hier um ein Duplikatsproblem.

2) Reine Ramirez Gil – Wilhelm Steinitz (31.12.1860)
Das ist noch merkwürdiger, da Reine Ramirez Gil ca. 100 Jahre nach Wilhelm Steinitz geboren wurde. Dazu existieren gleich mehrere Duplikate (die grün umrandete ist die hier untersuchte Partie).
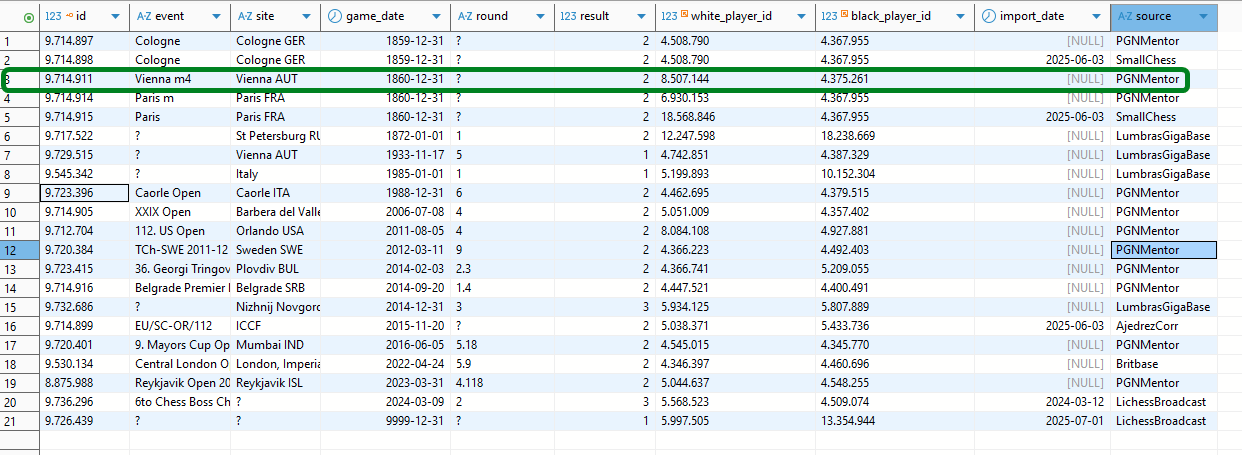
Bei der offensichtlich falschen Namenszuordnung wäre zu klären, ob diese in der ursprünglichen Datenbasis bereits vorlag oder erst durch den Import in unsere relationale Datenbank zustande kam. Auf jeden Fall sind Partien zwischen Steinitz und „Reiner“ aus 1860 dokumentiert und aus „1860“ wurde bei unserem Import das Datum „31.12.1860“ konstruiert. Doch die Namensverwechslung ist nicht sonderlich schlimm, denn sie ändert ja nichts am Partieverlauf und damit an der Bewertung.
Zumindest in diesem Beispiel ist auch ersichtlich, dass die Stellung vor dem ersten analysierten 21. Halbzug bereits bekannt war und es sich dabei um kein Duplikat handelt, was an den verschiedenen Spieler-IDs ersichtlich ist. Von daher gibt es keinen Grund, die Analyse-Resultate für diese Partie zu verwerfen.
3) Geza Maroczy – Wilhelm Steinitz 31.12.1899
Auch hier erscheint das Spieldatum aus der bloßen Jahreszahl konstruiert worden zu sein. Die Partie umfasst 87 Halbzüge und bis zum 43. Halbzug sind alle Züge aus einer vorherigen Partie bekannt.
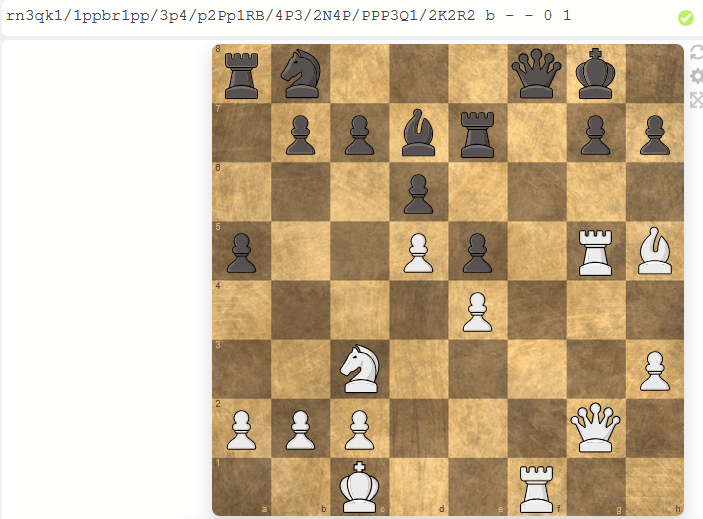
Tatsächlich ist die Partie weit fortgeschritten, was auch hier auf ein Duplikatsproblem hindeutet.

Anhand der selben Anzahl Halbzüge und der übrigen Idente kann man von den beiden unteren Partien der obigen Liste von Duplikaten ausgehen. Die erste Zeile würden wir wegen der selben Spieler-IDs und dem selben Jahr als wahrscheinlich unvollständiges Duplikat wie oben gesehen zurückweisen.
4) John Odin Howard Taylor – Wilhelm Steinitz 31.12.1865
Betrachten wir zunächst die Stellung, bis zu der Analysen verworfen wurden.
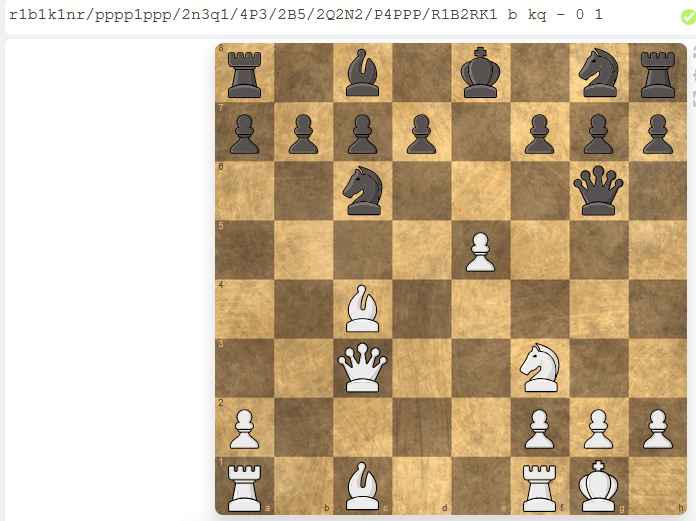
Diese Position sieht nach einem Übergang zwischen Eröffnung zum Mittelspiel und soweit stimmig aus.
Auch wurde diese Position in zahlreichen Vorgänger- und Nachfolge-Partien mit abweichenden Spielern erreicht. Offenbar haben wir es hier mit keinem Duplikatsproblem zu tun.
Daher erscheinen uns die Analyse-Ergebnisse für diese Partie als akzeptabel.
Fazit
Wie gerade gesehen, lässt sich das Problem unvollständiger Analysen hervorgerufen durch Partie-Duplikate auch mit einem relativ hohen Schwellwert von 50% und mehr nicht zweifelsfrei lösen. Auch tritt das Phänomen von Partien mit auffällig geringem Analyseanteil durchaus nicht nur in Partiensammlungen alter Meister auf, wo man eine per se schlechtere Datenqualität vermuten könnte. So haben zum Beispiel 62 der 382 hier analysierten Partien von Magnus Carlsen einen geringeren Analyseanteil als 60%. Stichproben zeigen uns aber, dass heutige Partien sehr oft nach bekanntem Muster bis weit ins Mittelspiel abgespult werden. Dadurch sinkt entsprechend der Analyseanteil auf natürliche Weise. Wir halten es daher für legitim, sämtliche Analyse-Ergebnisse zu berücksichtigen. Auch wenn unvollständig analysierte Partien einen Schönheitsfehler darstellen, sind die gewonnenen Kennzahlen daraus nicht falsch, sondern eventuell nur weniger aussagekräftig bezogen auf das betreffende Spiel. Auf der anderen Seite vermeiden wir damit das Risiko, Analyse-Ergebnisse durch einen falschen Duplikats-Verdacht zu verlieren.
Nachdem nun die Stockfish-Analysen abgeschlossen sind, werfen wir mit einem Adhoc-SQL-Skript nochmal einen Blick auf das erzielte Gesamtergebnis.
SQL-Code
select
p.id id,
p.name name ,
count(*) anzahl
from
game g
join player p on
(g.white_player_id = p.id
or g.black_player_id = p.id)
where
exists
(
select
1
from
position pp
join position_analysis pa on
(pp.id = pa.position_id)
where
g.id = pp.game_id)
group by
p.id,
p.name
order by
3 desc;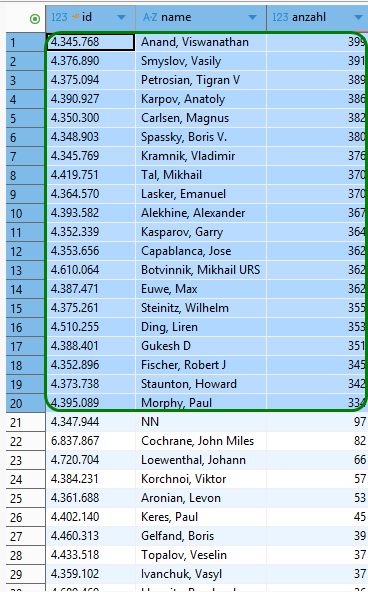
Die obige Liste zeigt zweierlei:
- Die Anzahl der analysierten Spiele pro Weltmeister variiert auf vergleichbarem Niveau wie erwartet.
- Quasi als Beifang wurden die Partien von über 2500 Gegnern gleichfalls mitbewertet. Wir werden diese Meister und Großmeister in den weiteren Untersuchungen allerdings nicht prominent herausstellen.
Im nächsten Kapitel widmen wir uns der Beschaffung weiterer abgeleiteter Kennzahlen auf Basis der jetzt vorliegenden Stockfish-Berechnungen.