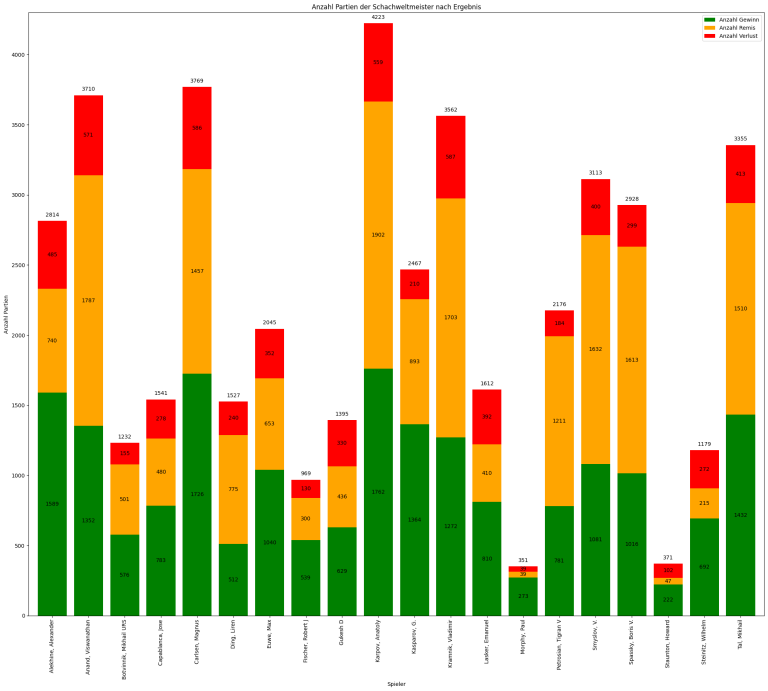
Wir wollen das aus Lumbra’s Gigabase extrahierte Partien-Archiv im PGN-Format in eine relationale Datenbank importieren.
Die Gründe für den Einsatz einer relationalen Datenbank sind
- der Wunsch nach einer normalisierten, redundanzfreien Datenbasis für die weiteren Analysen
- der Einsatz von SQL als strukturierter Abfragesprache für weitere Analysen mit Python und Jupyter Notebooks
- im Zuge des Datenimports sollen mit Python Datenbereinigungen vorgenommen werden.
- mit Hilfe der Python-Bibliothek python-chess und der Stockfish engine sollen beim Datenimport einzelne Züge auf Korrektheit und damit die zugehörigen Partien auf Gültigkeit überprüft werden.
- Zu jedem gültigen Zug soll ein Stellungsbild in der FEN-Notation gespeichert werden. Daraus soll in einem weiteren Schritt eine Hilfstabelle aufgebaut werden, um Spielstellungen bei der Analyse daraufhin zu prüfen, ob sie jemals zuvor in einer anderen Partie erreicht wurden.
- der schnelle indizierte Zugriff auf die gewünschten Daten
- gute DB-Zugriffsmöglichkeit von Python aus
- die Flexibilität, um weitere Hilfs- und Ergebnis-Tabellen zu definieren und leicht beladen zu können.
Datenbank-Installation
Die Datenbank-Software kann von mariadb.org für die gewünschte Umgebung heruntergeladen und installiert werden. Für die Einrichtung der Datenbank-Dateien selbst sind etwa 200-250 GB einzuplanen, wenn sämtliche Partien mit allen Zügen und Hilfstabellen gefüllt sind!
Hinweis:
Alle Informationen werden den Daten unseres PGN-Archives entnommen. Zusätzlich generieren wir zu den einzelnen Zügen jeweils die daraus entstehende neue Position. Anhand dieser Positionsbilder können wir bei der späteren Partien-Analyse leicht feststellen, ob diese jemals zuvor in einer anderen Partie erreicht wurde und damit als bekannt vorausgesetzt werden kann.
Zurück zur Datenbank-Software Installation. Wir können dabei die meisten Voreinstellungen übernehmen. Für den vordefinierten Datenbank-Superuser root müssen wir ein selbst gewähltes Passwort vergeben und den Dateipfad für das data directory müssen wir so wählen, dass dort ausreichend Platz für unsere Daten vorhanden ist, also mindestens 250GB.
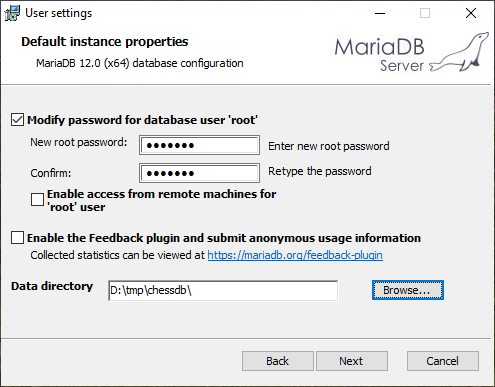
Für die weiteren Angaben können wir die Voreinstellungen übernehmen. Für den Zugriff auf MariaDB können wir das implizit mit installierte Programm HeidiSQL verwenden, etwa um die Datenbank-Verbindung einzurichten und Datenbank-Objekte wie Schemas und Tabellen anzulegen.
Wir ziehen es allerdings wegen der Fähigkeit, ER-Diagramme erstellen zu können, vor, DBeaver in der kostenlosen Community-Edition zu installieren.
DBeaver Community Installation
Wir laden von der DBeaver Homepage (Vorsicht: dbeaver.com ist falsch!) den Windows-Installer (bzw. den Installer für die gewünschte Plattform) herunter und führen ihn aus, indem wir alle Voreinstellungen übernehmen.
Beim anschließenden Start von DBeaver erhalten wir folgende Aufforderung, die wir entsprechend quittieren.
Wir wollen auch keine Beispieldatenbank erstellen und verneinen daher.
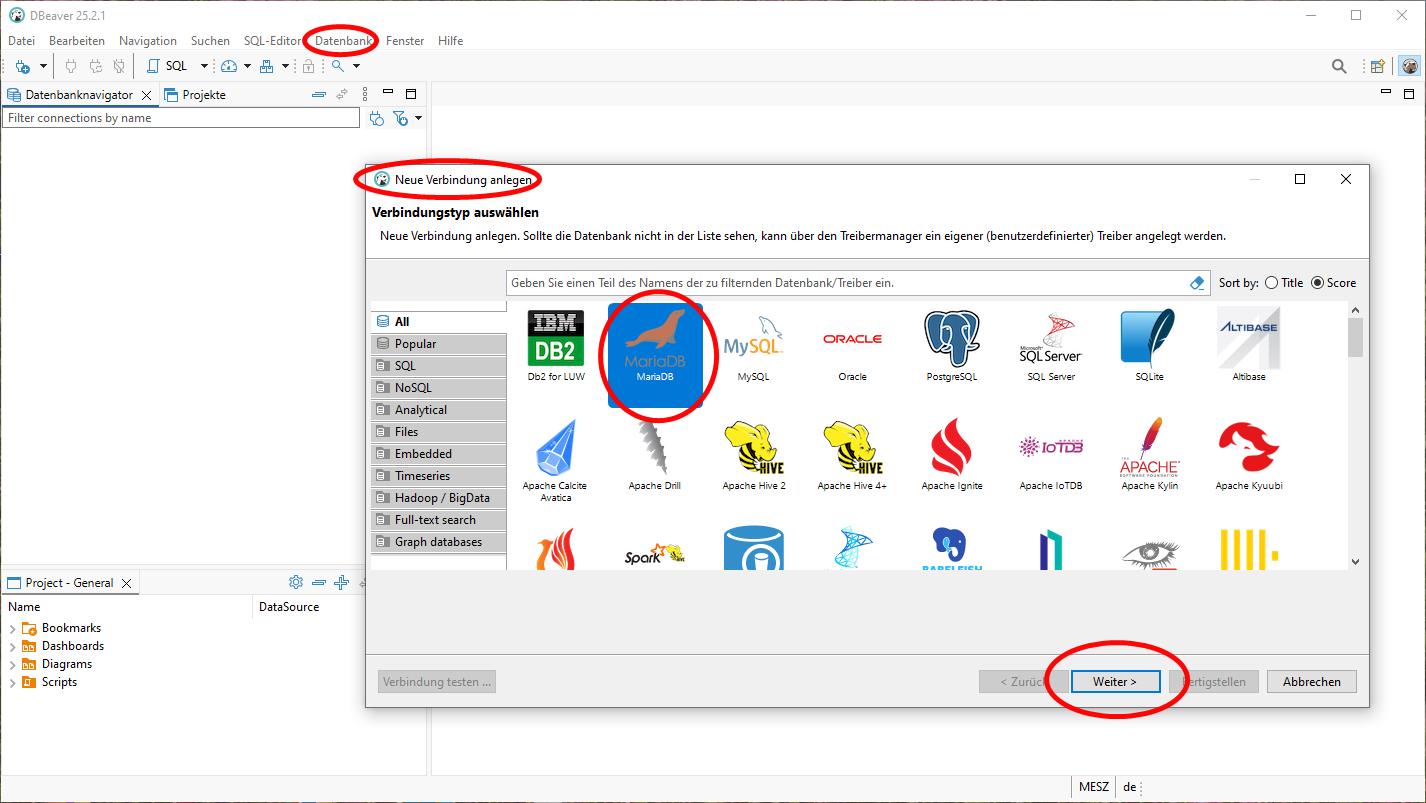
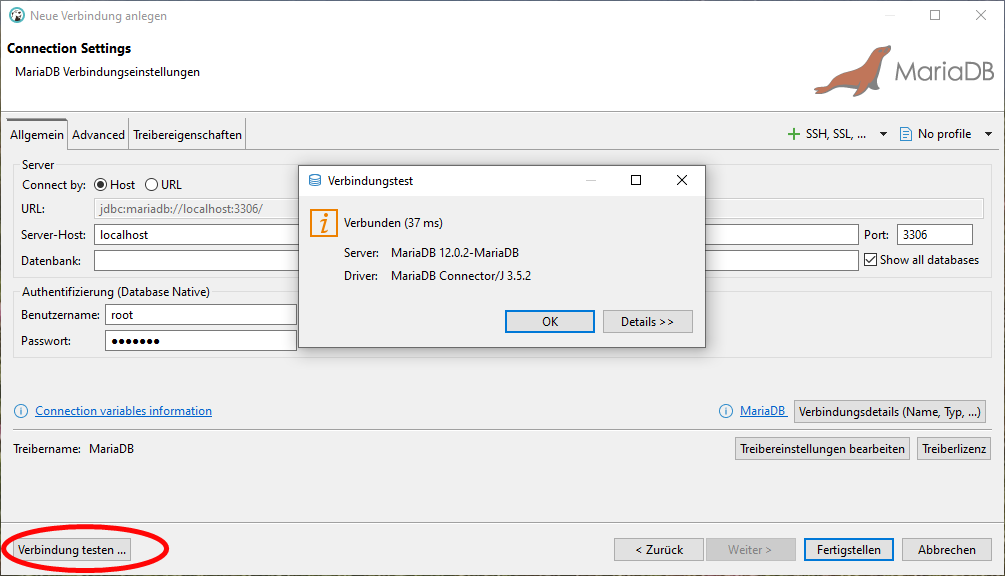
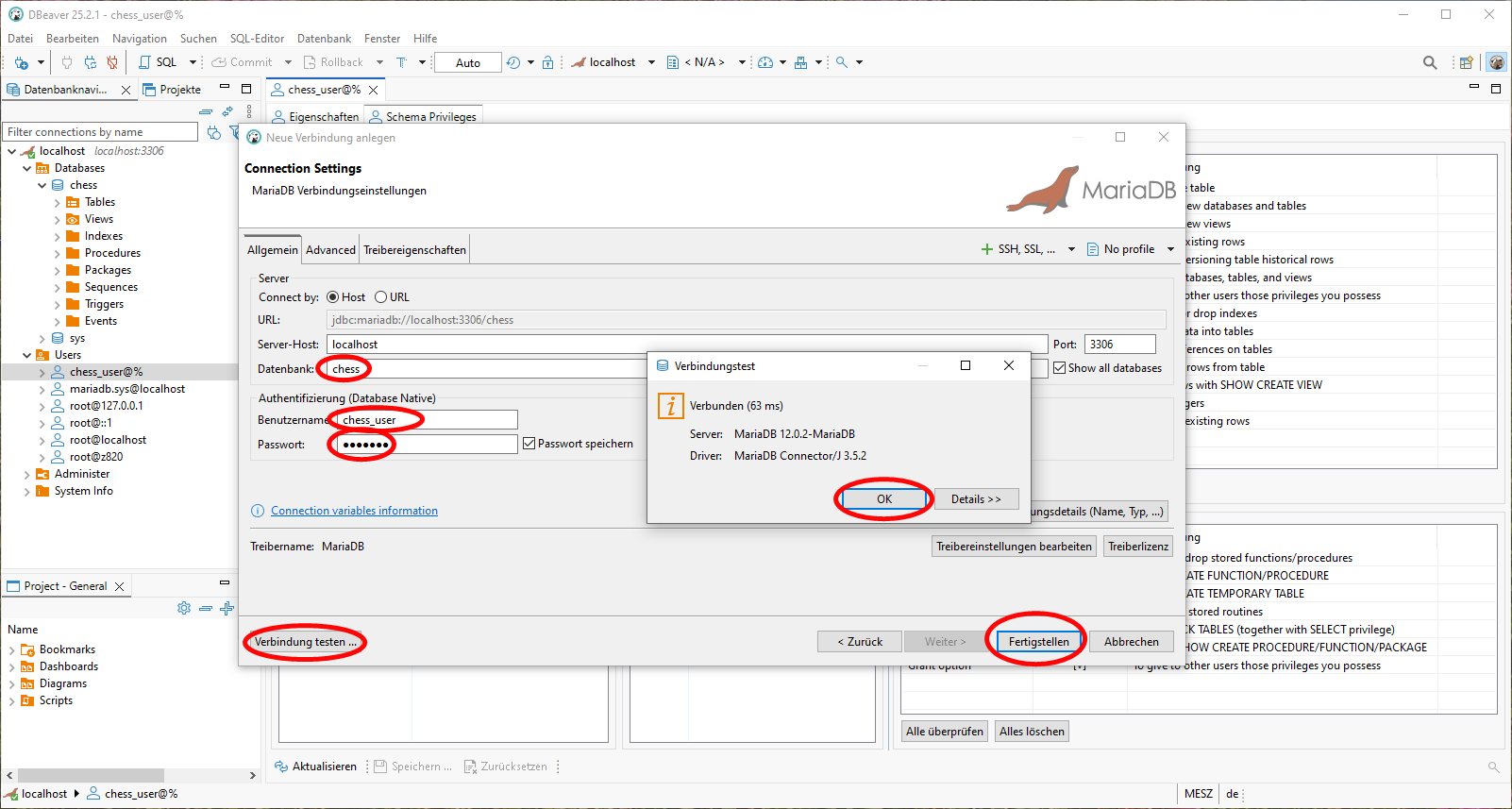
Stattdessen konfigurieren wir über den Menüpunkt Datenbank->Neue Verbindung anlegen mit den unten gezeigten Schritten zunächst die Verbindung zur Datenbank
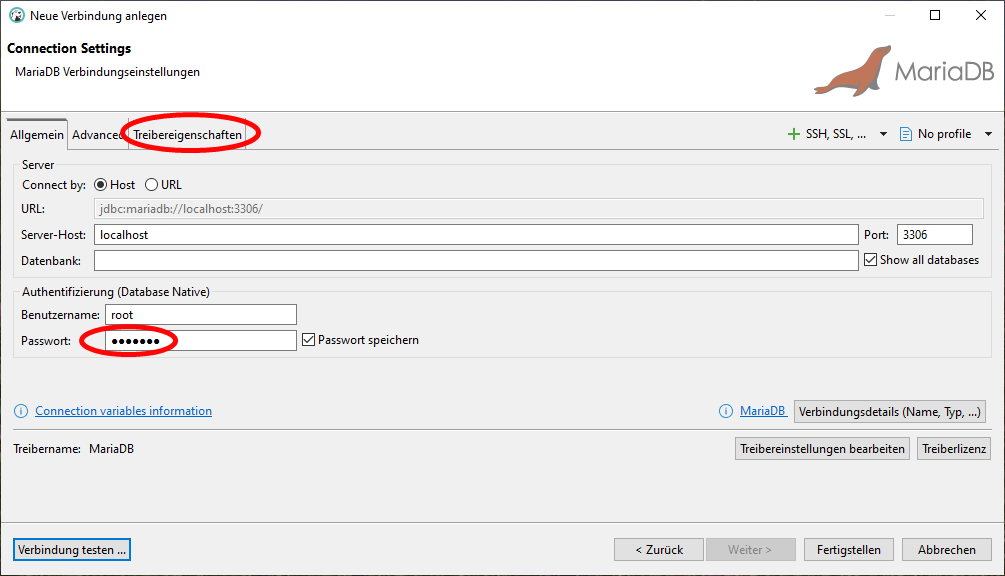
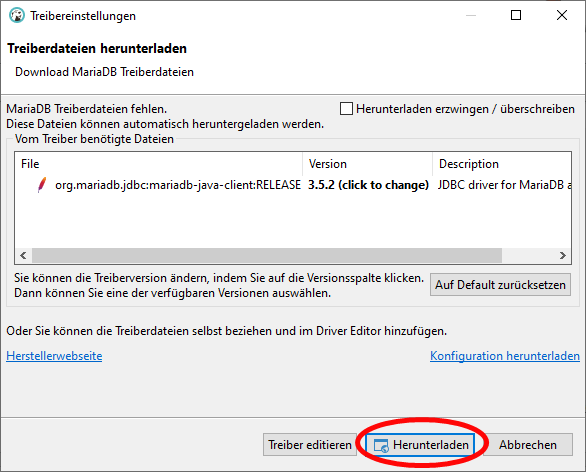
In den connection settings tragen wir das zuvor vergebene root Passwort ein. Danach klicken wir auf Treibereigenschaften und auf Herunterladen, um den zugehörigen Datenbank-Treiber zu installieren. Am Ende testen wir die angelegte Datenbank-Verbindung wie unten gezeigt.
Datenbank-Einrichtung
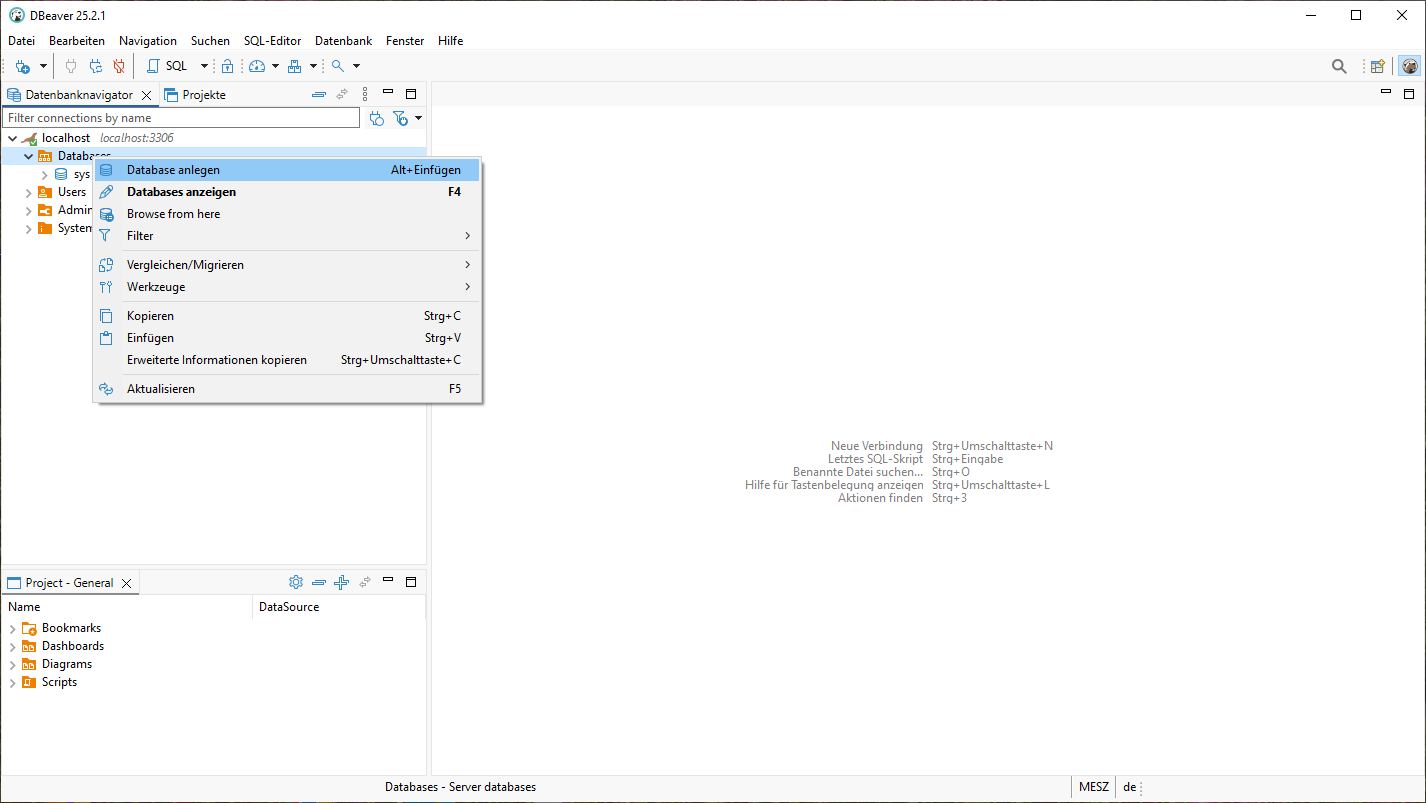
Im nächsten Schritt legen wir eine neue Datenbank mit dem Namen chess an und richten dafür einen speziellen DB-User chess_user an. Dazu nutzen wir DBeaver. Dort sehen wir auf der linken Seite die bisher definierten Verbindungen, in unserem Fall diejenige, die wir bereits für den root DB-User angelegt hatten. Wir erweitern die Ansicht durch Mausklicks und indem wir über dem Eintrag Databases die rechte Maustaste drücken, können wir mit Database anlegen unsere neue Datenbank erzeugen.
wir nennen die neue Datenbank chess und belassen die übrigen Voreinstellungen.
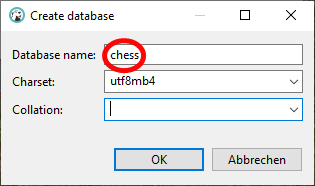
In unserer neuen chess Datenbank wollen wir alle unsere Tabellen und sonstigen Objekte vorhalten, die wir für unser Projekt benötigen. Dazu wollen wir auch einen separaten DB-User erstellen, dem wir nur die notwendigen Rechte einräumen, damit wir nicht etwa versehentlich die Datenbank beschädigen. Nennen wir unseren User einfach chess_user.
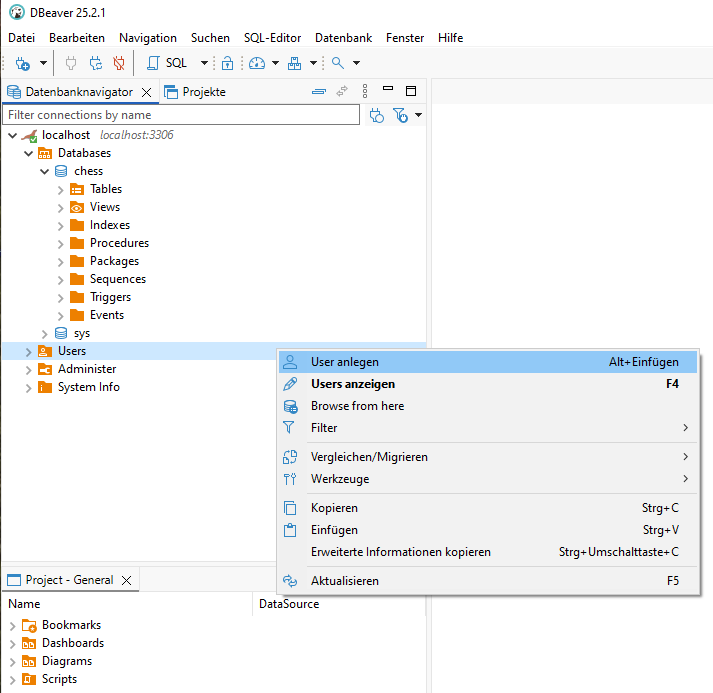
Wir tragen in dem darauf erscheinenden Dialogfenster den Usernamen und zweimal das Passwort ein. Danach wechseln wir dort in den Tabulator Schema Privileges, wo wir die Zugriffsrechte weiter regeln.
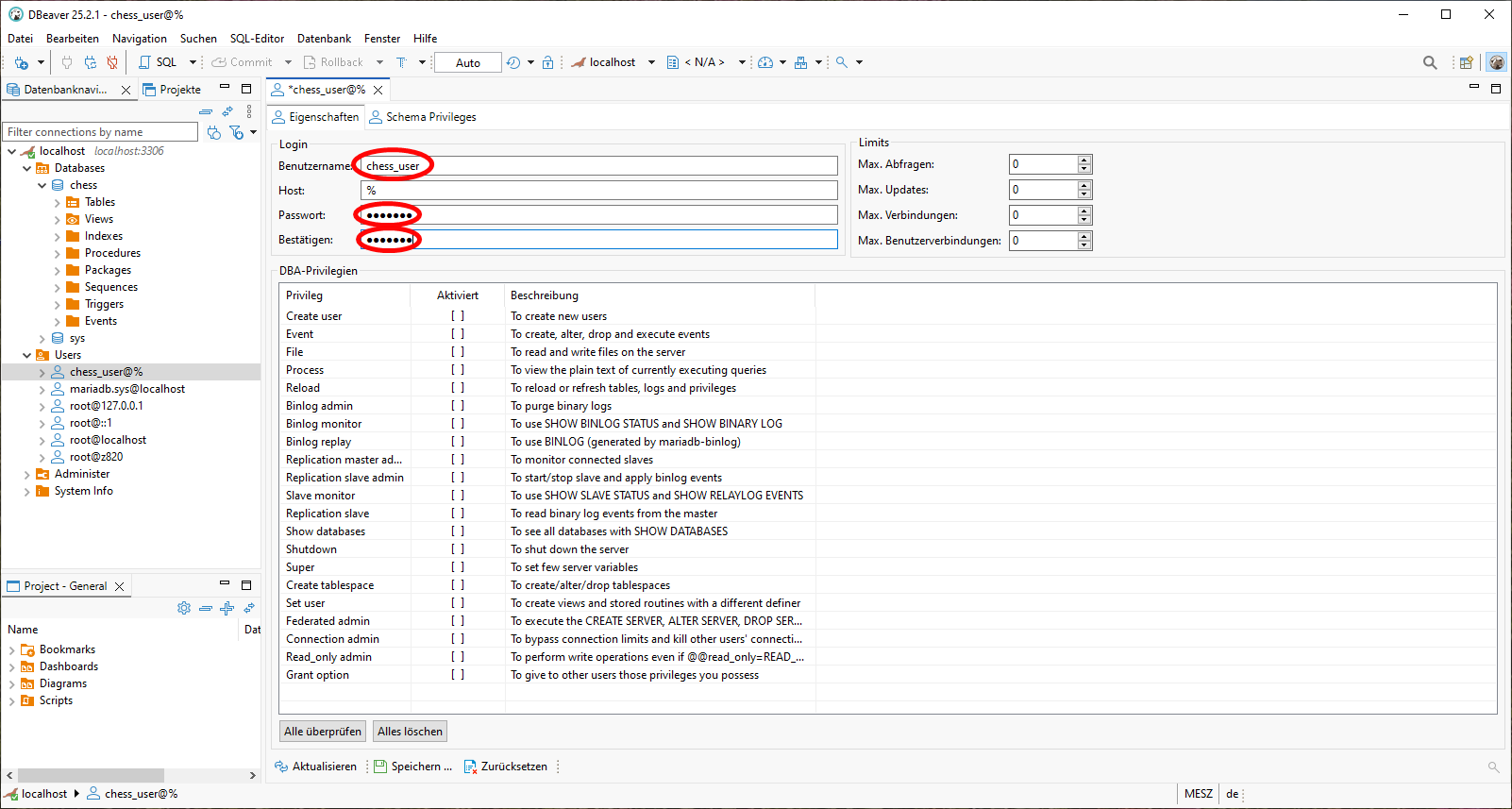
im Tabulator Schema Privileges wählen wir unter Kataloge unsere Datenbank chess aus und aktivieren sämtliche auf der rechten Seite dargestellten Privilegien. Zum Abschluss speichern wir unsere Angaben.
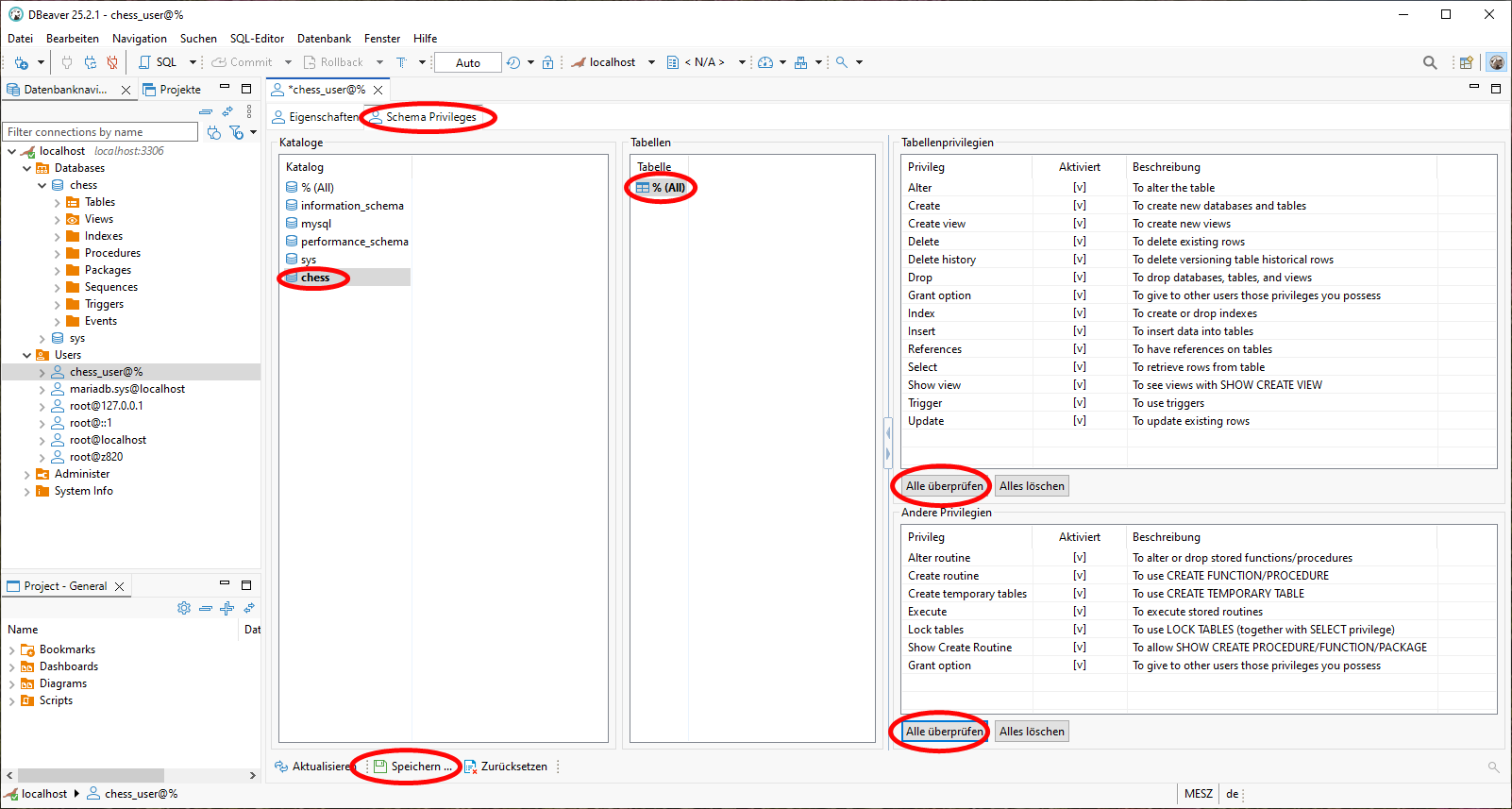
Daraufhin wird uns ein SQL-Skript angezeigt, welches den User chess_user erzeugt und diesem die gewünschten Privilegien erteilt. Wir lassen dieses Skript per Mausklick ausführen.
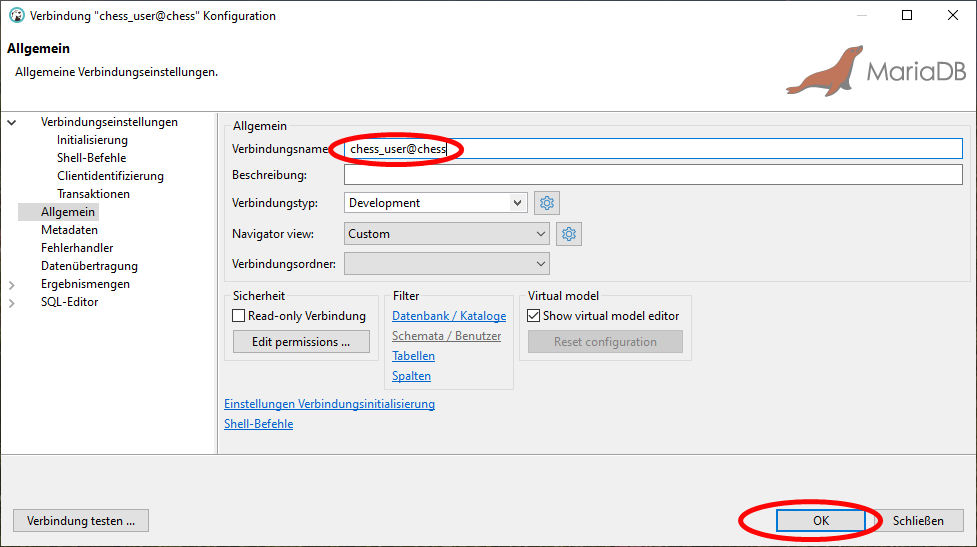
Da wir künftig nur noch mit dem neuen User chess_user in unserer chess Datenbank arbeiten wollen, legen wir dazu eine neue separate Datenbankverbindung für diesen an.
Da uns die Namen der beiden nun vorhandenen Verbindungen chess und localhost zu wenig instruktiv erscheinen, benennen wir diese anschließend noch in chess_user@chess und root@localhost um. Nun ist klar, mit welchen Benutzern wir wo zugreifen.
fachliches Relationen-Modell erstellen
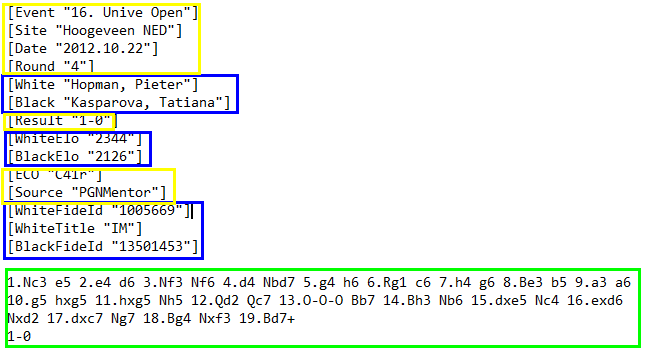
Im Bild unten erkennt man die Angaben zu einer Schachpartie im typischen PGN-Format. In den eckigen Klammern stehen in sog. tags Metainformationen – das sind Zusatzinformationen, die mit der gespielten Partie in Zusammenhang stehen.
mit unserem neuen User können wir nun in der chess Datenbank die erforderlichen Tabellen anlegen, die wir für den Datenimport aus dem PGN-Archiv benötigen. Dazu werfen wir noch einmal einen Blick auf die PGN-Struktur einer einzelnen Schachpartie.
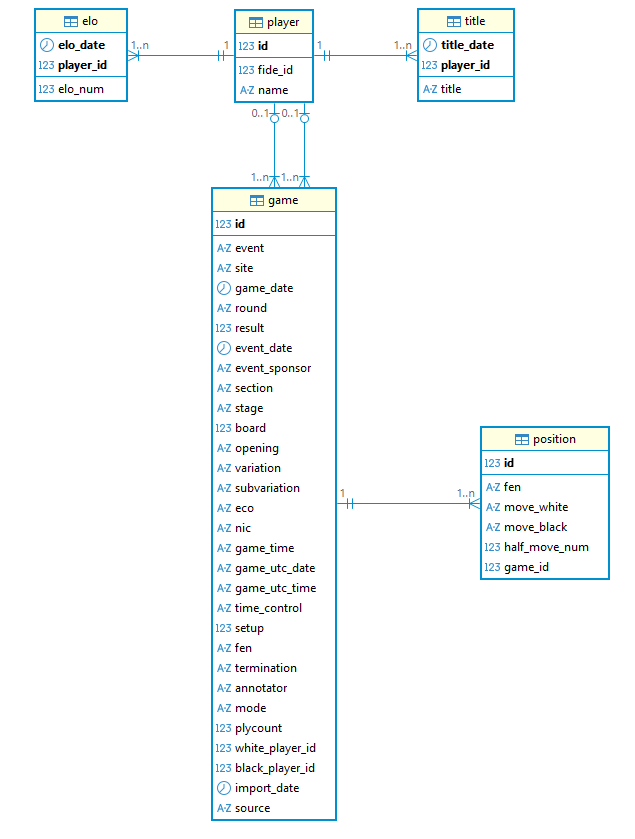
Insgesamt lassen sich alle Daten einer Partie im Relationen-Modell drei sogenannte Entitäten zuordnen, die dazu noch in Beziehung zueinander stehen.
- Spieler (können jeweils mehrere Partien als Weißer oder Schwarzer zugeordnet sein – unten blau markiert)
- Partie (kann aus vielen Zügen bestehen und ist jeweils einem Spieler mit den weißen und einem mit den schwarzen Steinen zugeordnet. Weitere Partie-Attribute sind z.B. das Datum, der Austragungsort sowie das Spielergebnis – unten gelb markiert)
- Halbzug (ein Zug besteht aus zwei Halbzügen von jeweils Weiß und Schwarz. Da jeder Halbzug zu einer neuen Position führt und wir diese mitführen wollen, trennen wir die Züge auf – unten grün markiert)
Wir sehen zum Beispiel im Diagramm unten, dass sich eine Partie (entspricht der Entität bzw. Tabelle game) immer auf zwei Spieler in der Entität bzw. Tabelle player bezieht. Und selbstverständlich achten wir beim späteren Datenimport darauf, den selben Spieler nicht mehrfach in die player Tabelle einzutragen!
Die Halbzüge einer Partie tragen wir in die Tabelle position ein. Die Begründung für diese Benennung haben wir oben gegeben.
Wenn man nun noch den zeitlichen Aspekt von ELO-Zahl und Titel eines Spielers berücksichtigt – diese können über die Zeit und damit von Spiel zu Spiel variieren, gelangt man direkt zum normalisierten Relationen-Modell, wie unten grafisch dargestellt. Wir sehen dort die jeweiligen (Primärschlüssel/Fremdschlüssel-) Beziehungen zwischen den Tabellen.
Hinweis: Die Skripte für die Erzeugung der Tabellen sind im zugehörigen Github-Repository zu finden und werden der Übersichtlichkeit halber hier nicht gezeigt.
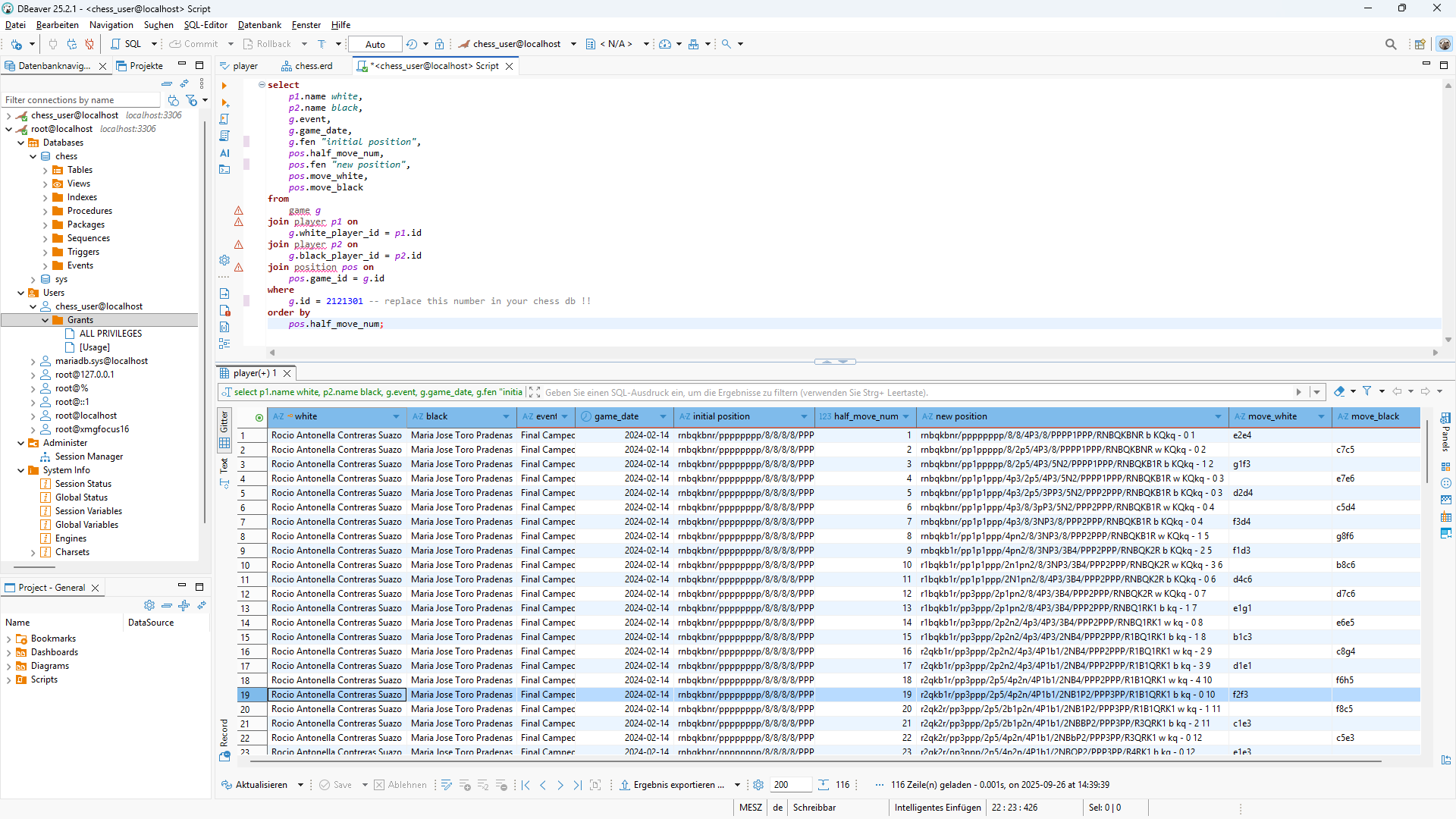
Wir werden später bei der Beschreibung des Import-Programmes für die Datenbank genauer auf weitere Einzelheiten eingehen. Zur Anschauung unserer Datenbank wollen wir beispielhaft ein beliebiges Spiel herausgreifen und uns ansehen. Beim Import in die Datenbank vergeben wir für die meisten Daten numerische technische IDs , die wir als eindeutigen Bezeichner (sogenannte Primärschlüssel) für einen Datensatz (auch Record, Zeile oder Entität genannt) verwenden. In unserem Beispiel greifen wir uns eine Partie aus der Tabelle game mit der ID=2121301 heraus und verknüpfen sie zweimal (über sog. Fremdschlüssel-Beziehungen) mit der Spieler-Tabelle player, jeweils für den Spieler mit den weißen und den schwarzen Steinen. Darüber hinaus wollen wir natürlich auch alle Züge und Positionen dieser Partie sehen und verknüpfen daher weiter mit der position Tabelle.
Außerdem wollen wir die Ergebnisliste aufsteigend nach der Zahl der Halbzüge (ein Zug besteht immer aus jeweils einem Halbzug von Weiß und Schwarz) sortiert sehen. Hier die zugehörige SQL-Abfrage:
select
p1.name white,
p2.name black,
g.event,
g.game_date,
g.fen "initial position",
pos.half_move_num,
pos.fen "new position",
pos.move_white,
pos.move_black
from
game g
join player p1 on
g.white_player_id = p1.id
join player p2 on
g.black_player_id = p2.id
join position pos on
pos.game_id = g.id
where
g.id = 2121301 -- replace this number in your chess db !!
order by
pos.half_move_num;Voilá
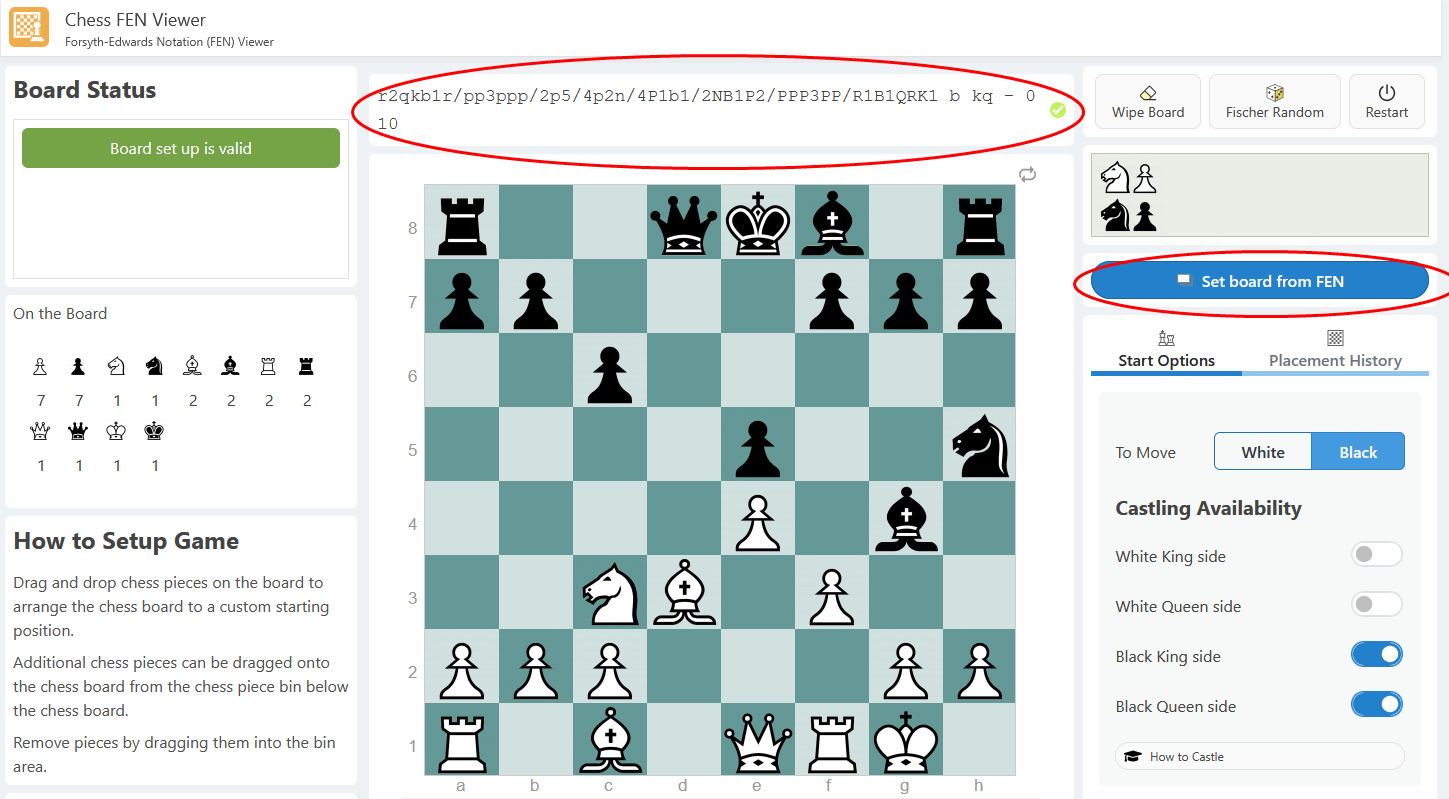
Wir wollen nun die Schach-Stellung (Position) nach dem zehnten Zug (19er Halbzug) von Weiß visualisieren. Dazu dekodieren wir den Wert aus der Spalte fen der Tabelle position „r2qkb1r/pp3ppp/2p5/4p2n/4P1b1/2NB1P2/PPP3PP/R1B1QRK1 b kq – 0 10“ online auf der Seite Chess FEN Viewer.
Da wir bei der späteren Analyse daran interessiert sind, bereits bekannte Positionen zu vernachlässigen, wollen wir hier gleich die dafür notwendige Nachschlage-Tabelle erzeugen – wir nennen sie fen_history. Drei Dinge sind dabei wesentlich:
- der Zeitbezug – alle jemals aufgetretenen Positionen werden in fen_history nur einmal abgelegt, und zwar mit dem jeweils ältesten Spieldatum.
- die Spalte fen_pos wird nicht mit der vollständigen FEN aus der Tabelle Position befüllt, sondern nur mit den ersten vier Gruppen davon (vgl. Aufbau Forsyth-Edwards-Notation) – die Anzahl der gespielten Halbzüge seit dem letzten Bauernzug oder dem Schlagen einer Figur (Gruppe 5) und die Nummer des nächsten Zuges (Gruppe 6) sind für den Positions-Vergleich irrelevant. Z.B. entstehen viele Positionen durch bloße Zugumstellung.
- um eine rasche Prüfung durchführen zu können, legen wir auf fen_pos einen eindeutigen Index.
CREATE TABLE `fen_history` (
`game_date` date NOT NULL,
`fen_pos` varchar(100) NOT NULL,
UNIQUE KEY `fen_history_fen_pos_IDX` (`fen_pos`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;Die Befüllung der Tabelle fen_history wird später rein Datenbank-technisch so erfolgen:
INSERT INTO fen_history (game_date, fen_pos)
select
MIN(t.game_date) game_date,
REGEXP_SUBSTR(t.fen, '[^ ]+ [^ ]+ [^ ]+ [^ ]+') as fen_pos
from
(
select
g.game_date,
p.fen
from
position p
join game g on
p.game_id = g.id
union all
select
STR_TO_DATE('1000-01-01', '%Y-%m-%d') game_date,
'rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1' fen_pos
) t
group by
REGEXP_SUBSTR(t.fen, '[^ ]+ [^ ]+ [^ ]+ [^ ]+')
;Aber wir greifen vor – zunächst müssen wir die Daten aus dem PGN-Archiv importieren…