Wir haben nun alle Zutaten beisammen, um mit dem Import zu beginnen.
- Partie-Daten in unserem PGN-Archiv
- Die Ziel-Tabellen in unserer chess MariaDB-Datenbank
- Python nebst aller notwendigen Pakete zur Erstellung des Import-Programmes
- ein github-Archiv zur Ablage aller unserer Programm-Artefakte und der Dokumentation
PgnImporter
Da wir das Import-Programm voraussichtlich nur ein einziges Mal benutzen werden, soll es möglichst simpel, aber doch einigermaßen wartbar und übersichtlich gehalten werden. Wir wollen den Code hier nicht zeilenweise in aller Ausführlichkeit beschreiben und setzen voraus, dass der verehrte Leser entweder selbst einige Programmierkenntnisse mitbringt oder kein Interesse an diesen Details hat.
Wir teilen unser Import-Programm in zwei Python-Dateien bzw. Module:
- chessdb.py Hier liegt der Code mit Bezug zur MariaDB, also für das Öffnen und Schließen der DB-Verbindung und den Insert-Anweisungen für das Beschreiben der Datenbank-Tabellen.
- pgn_importer.py enthält das Hauptprogramm und Hilfsfunktionen zur Datenbereinigung.
chessdb.py
Der Datenbank-lastige Code ist hier angesiedelt. Die Steuerung der Transaktionen findet im Hauptprogramm statt, chessdb.py stellt dafür lediglich die notwendigen Funktionen gekapselt nach außen zur Verfügung. Auch Record-Typen zur Datenübergabe werden hier initialisiert zur Verfügung gestellt. Das Schreiben in die Datenbank erfolgt lediglich über Insert-Anweisungen (bei player mit update-Klausel im Falle von Vorhandensein) per Bind-Variablen. Die ID-Spalten, die in den meisten Tabellen als Surrogatschlüssel verwendet werden, sind als „auto_increment“ definiert, werden also von der Datenbank selbstständig vergeben. Die Funktionen, welche die Insert-Anweisungen durchführen, liefern deren Wert als Rückgabe-Parameter dem aufrufenden Programm. Dieses kann die Werte dann weiterverwenden, z.B. zur Nutzung als Fremdschlüssel für weitere Tabellen-Einträge.
Laufzeitoptimierungen wie der Einsatz von Bulk-Anweisungen oder Parallelisierung wurden nicht vorgenommen. Der gesamte Importvorgang dauerte für ca. 9,5 Millionen Partien sowie deren Züge und Stellungsbilder ca. 2-3 Tage auf einem modernen Notebook.
Das Passwort in der connect()-Anweisung im Klartext hineinzuschreiben ist zugegebenermaßen kein guter Stil, aber in Anbetracht der Einweg-Funktionalität vielleicht verzeihbar.
pgn_importer.py
Dieses Modul beinhaltet das Hauptprogramm zum Lesen aller Spiele aus unserer PGN-Datei. Deren Name und Pfad sind im Programm fixiert – hier muss evtl. eine manuelle Anpassung erfolgen! Etwas mehr Mühe wurde sich beim Bereinigen der Daten und der Fehlerbehandlung gemacht. Wie bereits geschrieben sollen nur gültige und mit den notwendigsten Angaben versehene Partien in unsere Datenbank Eingang finden
- Spiele, die von den klassischen Regeln abweichen (z.B. Schach960), werden nicht importiert.
- Ein Spiel wird entweder vollständig mit allen Zügen oder gar nicht importiert. Dies wird über die Transaktions-Behandlung sichergestellt.
- Die Inhalte der interessierenden Tags werden überprüft und ggf. soweit als möglich ergänzt. Unbehebbare Fehler führen dazu, dass diese Partie nicht importiert wird.
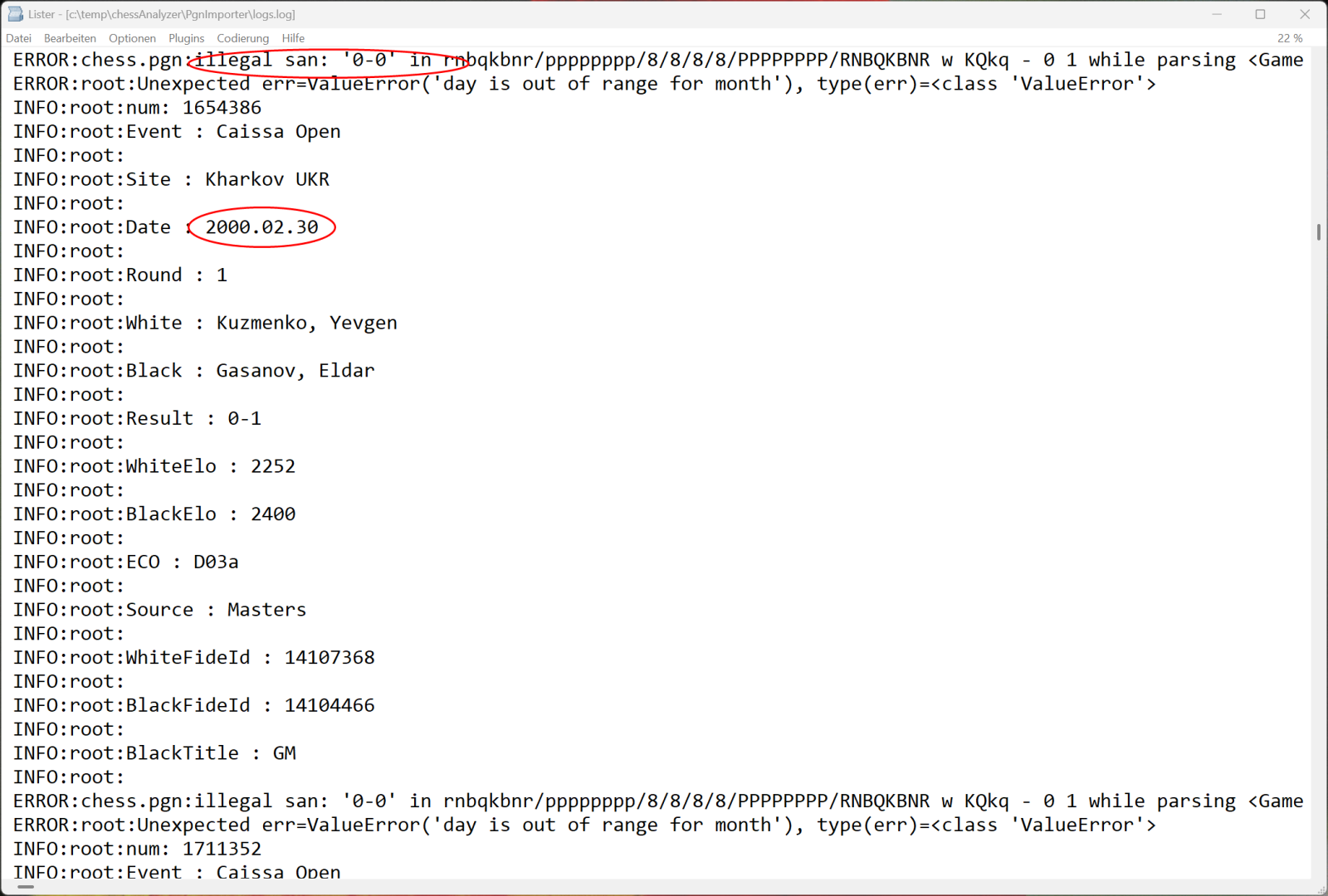
- Bei Tags mit ungültigen Datumswerten wird versucht, diese zu reparieren („2025.02.??“ wird zu „2025.02.28“ ergänzt, „????.??.??“ zu „9999.12.31“ etc.).
- Die möglichen Werte des Result-Tags („1-0“, „0-1“, „1/2-1/2“, sonst) werden auf die Werte 1, 2, 3 und 4 gemappt.
- Falls die Anfangsstellung per FEN-Tag nicht angegeben ist (was eigentlich bei allen Partien bis auf Vorgabepartien der Fall ist) , wird die FEN explizit auf den Standardwert „rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq – 0 1“ dafür gesetzt.
- Beim Eintrag der Züge zu einer Partie wird gleichfalls die resultierende Stellung als FEN konstruiert und in der Tabelle position gespeichert.
Die Ausführung des Programms geschieht in der Konsole einfach durch den Aufruf von Python mit dem Namen des Hauptprogramms als Parameter. Im Idealfall beendet sich das Programm nach einiger Zeit wortlos und die Log-Datei im gleichen Verzeichnis ist möglichst leer.
Logging
Fehlermeldungen, die beim Import einzelner Partien z.B. durch ungültige Werte auftreten, werden in eine Log-Datei geschrieben.
Zum Glück sind fast alle Partien importierbar, so dass wir nun erste Datenbank-Abfragen ausführen können. Zunächst interessieren uns die Anzahl Spieler und Partien.
select count(*) from player;
525945
select count(*) from game;
9590557Die Anzahl der Partien entspricht den Erwartungen. Die Vielzahl der Spieler erstaunt, aber erscheint auch plausibel vor dem Hintergrund, dass hier auch Schachspieler aller Nationen im unteren bis mittleren Ranking vertreten sind. Bei der Durchsicht der Namen fällt trotzdem auf, dass dort etliche zweifelhafte und nicht eindeutige Einträge und wahrscheinlich auch Duplikate durch nicht eindeutige Namen vorhanden sind.
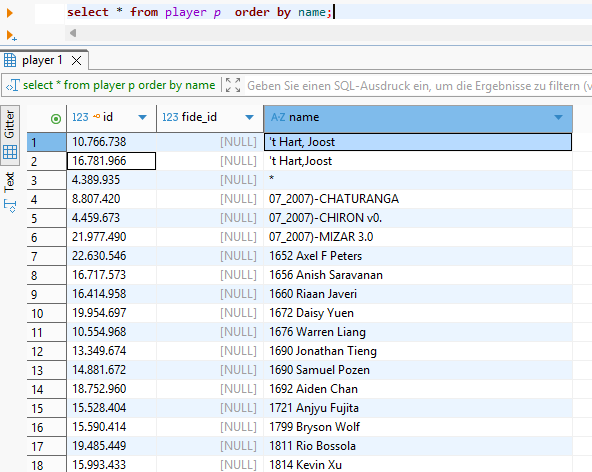
Doch uns interessieren in erster Linie die Spitzenspieler. Sehen wir uns daher die Liste der Weltmeister mit der Anzahl ihrer in der Datenbank enthaltenen Partien an.
SQL-Code
select
p.*,
count(g.id) "Anzahl Spiele"
from
player p
join game g on
(p.id = g.black_player_id
or p.id = g.white_player_id )
where
p.name in ('Staunton, Howard', 'Morphy, Paul', 'Steinitz, Wilhelm', 'Lasker, Emanuel', 'Capablanca, Jose', 'Alekhine, Alexander', 'Euwe, Max',
'Botvinnik, Mikhail URS', 'Smyslov, Vasily', 'Smyslov, V.', 'Tal, Mikhail', 'Petrosian, Tigran V', 'Spassky, Boris V.', 'Fischer, Robert J', 'Karpov, Anatoly',
'Kasparov, Garry', 'Kasparov, G.', 'Kramnik, Vladimir', 'Anand, Viswanathan', 'Carlsen, Magnus', 'Ding, Liren', 'Gukesh D')
group by
p.id,
p.fide_id,
p.name
order by
p.nameMan erkennt sogar hier das Problem der nicht immer eindeutigen Namen – da hilft nur genaues Hinsehen bei den zugeordneten Partien, etwa ob der zeitliche Rahmen und das Spielniveau passen. Und obwohl einzelne Falschzuordnungen immer möglich sind, erscheint uns das Gesamtergebnis plausibel zu sein.
Lookup-Tabelle für Schachpositionen
wie bereits angedeutet, wollen wir bei der bevorstehenden Spielanalyse nur Züge bewerten, die in gleicher Ausgangsposition zuvor noch nie ausgeführt wurden. Bei vielen Eröffnungen resultieren durch Zugumstellung oft die selben bekannten Stellungsbilder. Da wir die kreativen Fähigkeiten der Spieler messen wollen und nicht deren Gedächtnis, nehmen wir daher kurzerhand diese Züge einer Partie aus der Wertung.
Und selbstverständlich genügt es nicht nur zu prüfen, ob die durch den jeweiligen Zug erreichte Stellung bereits zu einem früheren Datum bekannt war, sondern es ist auch essentiell zu wissen, wer danach am Zug ist, wie das Beispiel unten zeigt.
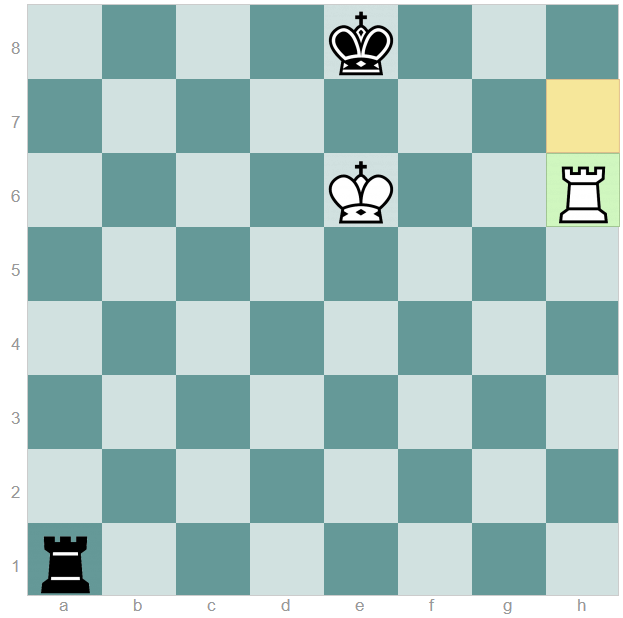
Doch diese Information liegt uns vor, da sie in der FEN-Notation codiert ist! Auf der anderen Seite enthält die FEN auch Informationen, die wir unberücksichtigt lassen wollen. Die „Anzahl der gespielten Halbzüge seit dem letzten Bauernzug oder dem Schlagen einer Figur“ (Feld 5 in der FEN-Notation) und die „Nummer des nächsten Zuges“ (Feld 6 in der FEN-Notation) sind für unsere Bewertung praktisch irrelevant und wir schenken ihr daher keine Beachtung.
Technische Lösung
Wir halten in der Tabelle fen_history alle historisch erreichten Schachpositionen einschließlich der Anfangsposition jeweils nur einmal fest, zusammen mit dem Datum, wann sie zuerst erreicht wurde. Dazu kürzen wir die gespeicherte FEN um die beiden letzten Bestandteile (Feld 5 und 6).
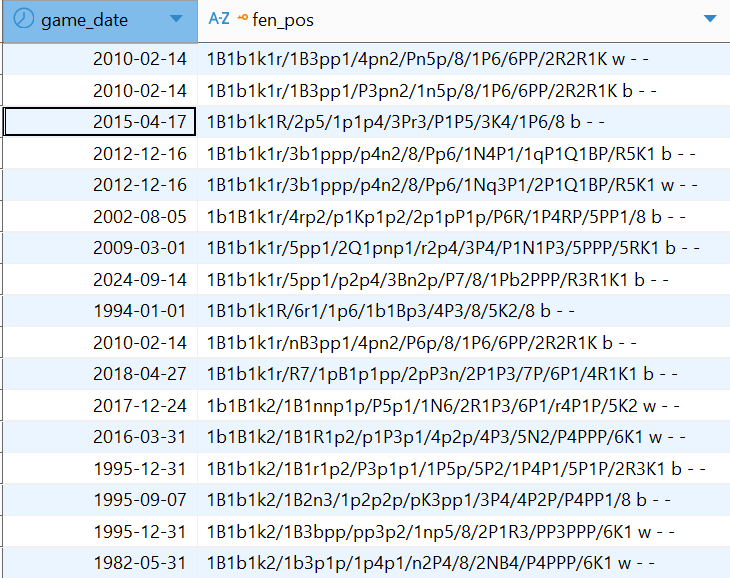
Sehen wir uns folgende Partie des aktuellen Weltmeisters Dommaraju Gukesh an:
Die Partie ging über 21 Züge und endete Remis. Die Partie ist auch in unserer Datenbank vorhanden. Wir wollen nun alle Züge dieser Partie sehen unter Nichtberücksichtigung derjenigen Züge, die von einer bereits bekannten Ausgangsstellung zu einer ebenfalls bekannten Endstellung führen. Zwar ist dies kein sicherer Beweis, dass der gleiche Zug in der selben Stellung tatsächlich zuvor durchgeführt wurde, aber die Evidenz erscheint uns hoch genug für einen Ausschluss solcher Züge.
Die SQL-Anweisung für die Datenbankabfrage ist leicht zu formulieren.
SQL-Code
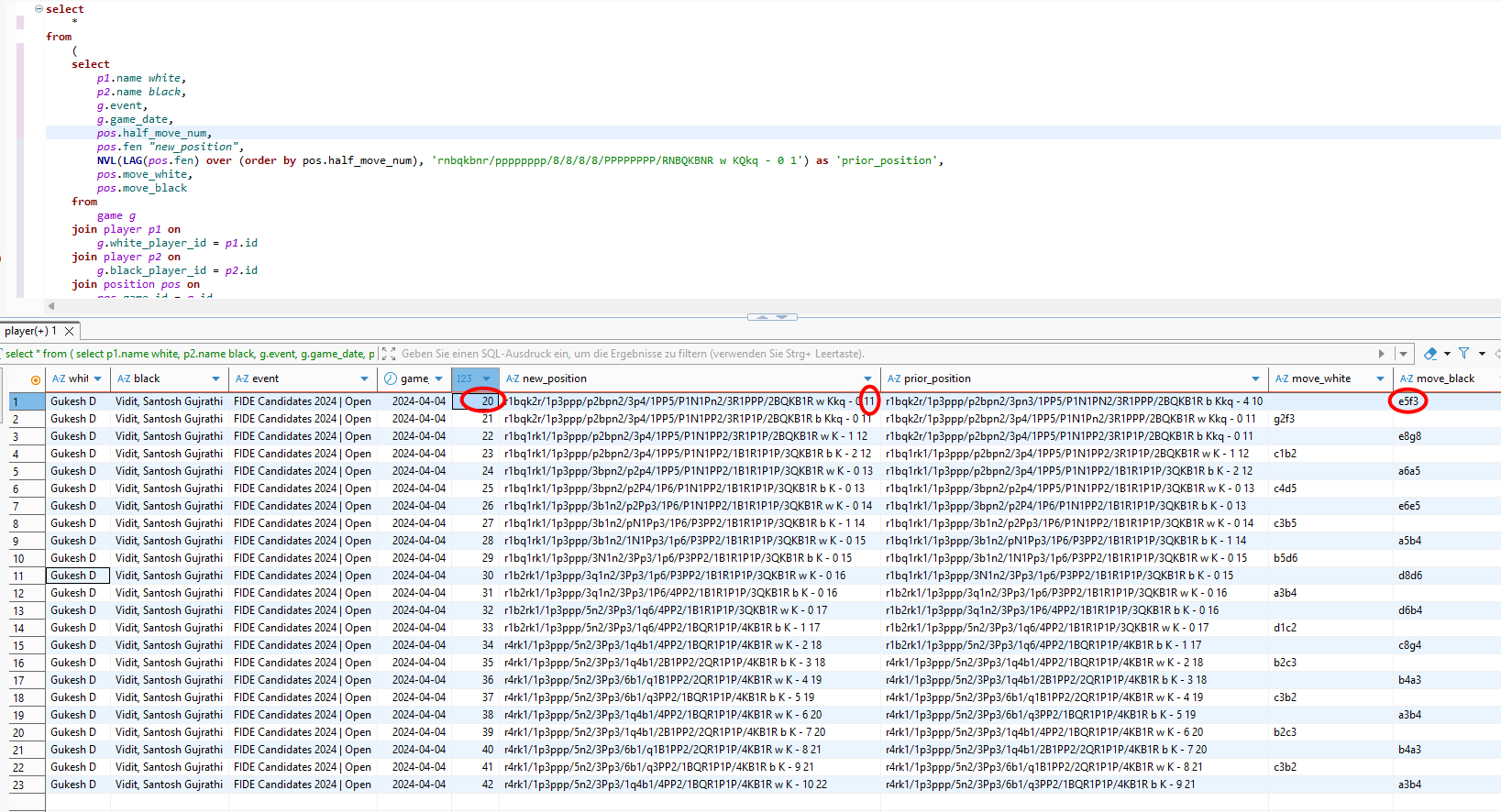
select
*
from
(
select
p1.name white,
p2.name black,
g.event,
g.game_date,
pos.half_move_num,
pos.fen "new_position",
NVL(LAG(pos.fen) over (order by pos.half_move_num), 'rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1') as 'prior_position',
pos.move_white,
pos.move_black
from
game g
join player p1 on
g.white_player_id = p1.id
join player p2 on
g.black_player_id = p2.id
join position pos on
pos.game_id = g.id
where
g.id = 3426067
) t
-- replace this number in your chess db !!
where
not (exists (
select
1
from
fen_history h
where
h.fen_pos = REGEXP_SUBSTR(t.new_position, '[^ ]+ [^ ]+ [^ ]+ [^ ]+')
and h.game_date < t.game_date)
and exists (
select
1
from
fen_history h
where
h.fen_pos = REGEXP_SUBSTR(t.prior_position, '[^ ]+ [^ ]+ [^ ]+ [^ ]+')
and h.game_date < t.game_date))
order by
t.half_move_num;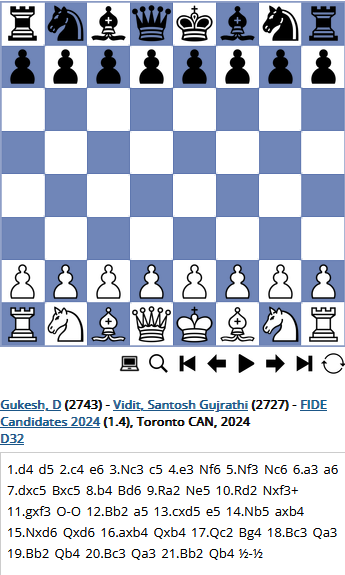
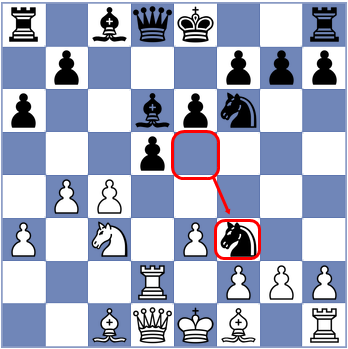
Das Ergebnis überrascht nicht – beide Spieler absolvieren ihre Züge auf bekanntem Terrain. Erst im zehnten Zug wartet Schwarz mit einer praktischen Neuerung (Se5-f3) auf. Ob es sich dabei auch um eine theoretische Neuerung handelt, lässt sich aufgrund der vorliegenden Daten nicht entscheiden. Immerhin könnte dieser Zug an anderer Stelle bereits untersucht, aber nie real gespielt worden sein. Man muss sogar davon ausgehen, dass zumindest der Ausführende diesen Zug im stillen Kämmerchen bereits eingehend analysierte!
Zur Anschauung hier die Stellung nach 10) Se5-f3
Ein weiteres Beispiel ist die bekannte sechste Partie aus dem Weltmeisterschaftskampf Fischer-Spasski 1972 in Reykjavik, in der Schwarz erst im 18. Zug(!) eine Neuerung anbrachte.

Wir haben nun alle Voraussetzungen geschaffen, um die nächsten Schritte für die Partien-Analyse auszuführen. Welche Kennzahlen uns dabei genau interessieren und wie wir sie uns beschaffen können, klären wir im nächsten Kapitel.