Wir haben im vorherigen Kapitel erörtert, mit welcher Parametrisierung wir unsere Spielanalysen durchführen wollen. Dazu haben wir die Kennzahlen festgelegt, die wir ermitteln und speichern werden. Glücklicherweise ist unsere Partiensammlung weitgehend frei von Duplikaten. Wenn wir also die Partien der Schachmeister A und B analysieren werden, können wir davon ausgehen, dass wir dabei die Partien, die A und B gegeneinander gespielt haben, nur einmal analysieren müssen.
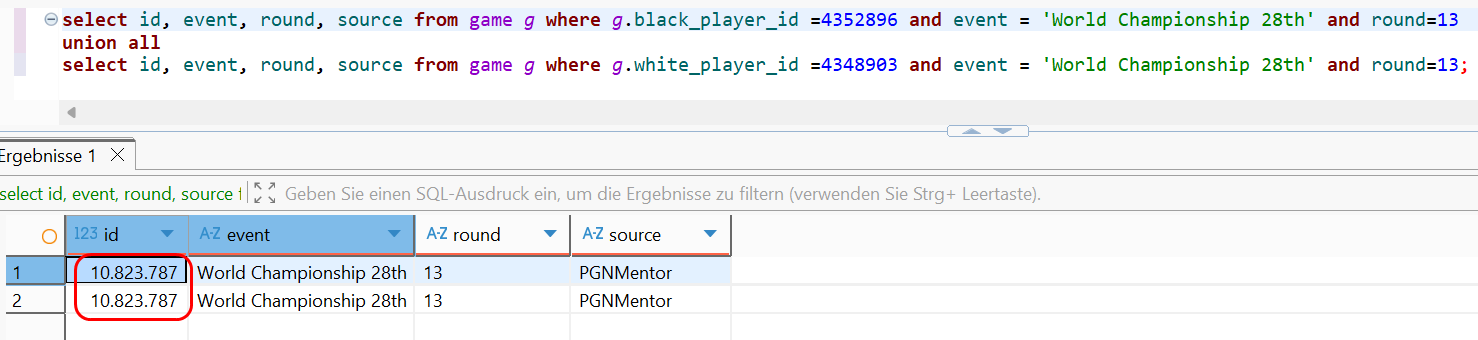
Wir überprüfen diesen Sachverhalt anhand unseres Parade-Beispiels der 13. Matchpartie zwischen Bobby Fischer und Boris Spasski 1972 und erkennen, dass beide unabhängig voneinander ermittelten Partien die selbe Entität in der Tabelle game sind.
Was jetzt noch fehlt, sind die Datenbank-Tabelle zur Speicherung unserer Analyse-Ergebnisse sowie das zugehörige Python-Programm, das die Partien eines ausgewählten Spielers entsprechend unseren Vorgaben analysiert und die Resultate in der Datenbank speichert.
Die Kennzahlen-Tabelle
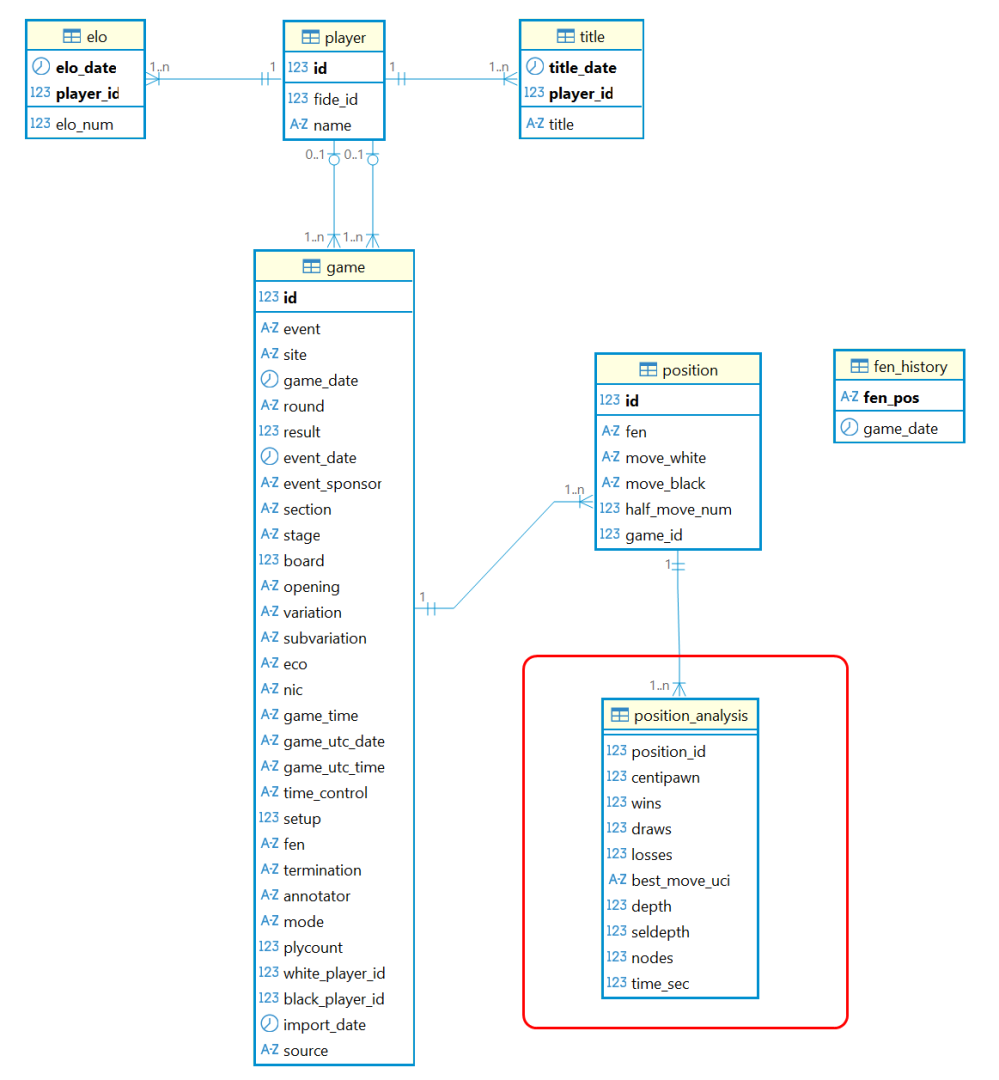
Da wir die Positionen mit den entsprechenden Halbzügen eines Spiels analysieren werden, liegt es nahe, unsere neue Kennzahlen-Tabelle als Detail-Tabelle von position zu modellieren. Das folgende Entity-Relation-Modell gibt diesen Sachverhalt wieder. Die Bedeutung der Spalten in der neuen Tabelle position_analysis wurde im letzten Kapitel bereits erklärt.
Das Analyse-Programm
Wir können den Python-Code unseres Prototypen aus dem letzten Kapitel für unsere Zwecke wiederverwenden, um fehlende Teile wie die Datenbankanbindung zu ergänzen und den letzten Schliff anzubringen.
Hier die wesentlichen Design-Entscheidungen:
- das Analyse-Programm soll als Parameter das Datenbank-Passwort und die Spieler-ID erhalten. Das Passwort ist dabei verdeckt einzugeben.
- pro Lauf wird das Programm in fester Reihenfolge sämtliche Partien des betreffenden Spielers aus der Datenbank lesen und jede einzelne Position in Zugreihenfolge analysieren. Ausgenommen sind bereits bekannte Positionen. Dies wird anhand der Tabelle fen_history geprüft.
- für jede analysierte Position wird eine Ergebniszeile in die Tabelle position_analysis geschrieben.
- erst wenn die Kennzahlen aller Züge einer Partie vollständig in position_analysis gespeichert wurden, werden diese Daten atomar in einer Transaktion festgeschrieben (commit).
Damit soll nach einem möglichen Fehlerabbruch das Programm besser wiederaufgesetzt werden können. Dazu wird für die jeweils zu analysierende Partie vorher kurz geprüft, ob bereits Einträge in der Tabelle position_analysis vorliegen. Falls ja, wird die zeitaufwändige Analyse dieser Partie übersprungen. - das Analyse-Ergebnis „Matt in x Zügen“ rechnen wir in einen entsprechenden centipawn-Wert „32000 – x“ um. Das vereinfacht die späteren Berechnungen.
- Neben Fehlermeldungen wollen wir auch Log-Einträge pro analysierter Partie mit deren Laufzeit und Anzahl analysierter Züge erzeugen. Damit können wir den Zeitbedarf für weitere Analysen abschätzen.
- wir werden das Analyse-Programm modularisieren, indem wir den Datenbank-lastigen Code vom Hauptprogramm mit den Spielanalysen trennen.
- Unser fertiges Python-Programm soll aus Effizienzgründen nativ unter MS-Windows 11 Pro in einer Windows Eingabeaufforderung laufen. Die Programm-Parameter für Hash und Threads werden auf die konkrete Hardware-Ausstattung eingestellt.
- Unser erster Testfall soll die Analyse der Partien des Spielers John William Schulten sein. Der ist einerseits als Gegenspieler von Paul Morphy hinreichend bekannt und andererseits ist sein Schacherbe mit lediglich 8 Partien recht überschaubar.
Unser fertige Hauptprogramm ChessAnalyser.py sieht wie folgt aus:
Python Code
import argparse
import getpass
import sys
import logging
import chessdb as db
from dataclasses import dataclass
import chess
import chess.engine
# performance tuning parameters
num_threads = 20
hash_mb = 48000
# analysis limits
max_depth = 30
movetime_sec = 15
num_moves_to_return = 1
mate_centipawns = 32000
engine_path = "c:/portable/stockfish/stockfish-windows-x86-64-avx2.exe"
# configure chess engine
engine = chess.engine.SimpleEngine.popen_uci(engine_path)
engine.configure({"Threads": num_threads, "Hash": hash_mb})
search_limit = chess.engine.Limit(depth=max_depth, time=movetime_sec)
def analyze_position(p_fen, p_pos_id):
position_analysis = db.PositionAnalysisRecord()
position_analysis.position_id = p_pos_id
board = chess.Board(p_fen, chess960=False)
stm = board.turn
info = engine.analyse(board, search_limit)
logging.info(f"Analyzed position: {info}")
position_analysis.best_move_uci = info["pv"][0].uci()
position_analysis.depth = info["depth"]
position_analysis.seldepth = info["seldepth"]
position_analysis.nodes = info["nodes"]
position_analysis.time_sec = info["time"]
# get score and wdl
eng_score = info.get("score")
if eng_score is not None:
position_analysis.centipawn = eng_score.white().score(
mate_score=mate_centipawns
)
# get wdl
wdl = eng_score.wdl() # win/draw/loss info point of view is stm
position_analysis.wins, position_analysis.draws, position_analysis.losses = (
wdl[0],
wdl[1],
wdl[2],
)
return position_analysis
def analyse_game(p_game_id):
try:
# make sure analysis does not already exist
if db.position_analysis_exists(p_game_id):
logging.info(f"Game {p_game_id} already analyzed, skipping.")
return
logging.info(f"Start analyzing game {p_game_id}.")
for position_row in db.get_positions(p_game_id):
pos_id = position_row[0]
fen = position_row[1]
position_analysis = analyze_position(fen, pos_id)
db.insert_position_analysis(position_analysis)
db.commit()
logging.info(f"Finished analyzing game {p_game_id}.")
except Exception as e:
logging.error(f"Error analyzing game {p_game_id}: {e}")
db.rollback
def main():
# use basic logging
logging.basicConfig(
filename="logs.log",
level=logging.INFO,
format="%(asctime)s %(levelname)-8s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
filemode="w",
)
# get command line arguments IDplayer and password
parser = argparse.ArgumentParser()
parser.add_argument(
"-i",
"--IdPlayer",
type=int,
required=True,
help="player ID from chess database",
)
parser.add_argument(
"-p",
"--password",
type=str,
required=True,
default='',
nargs='?',
help="database password for chess_user",
)
args = parser.parse_args()
# If password not provided, prompt securely
if not args.password:
try:
args.password = getpass.getpass(prompt="Enter database password: ")
except (KeyboardInterrupt, EOFError):
print("\nPassword input cancelled.")
sys.exit(1)
# Validate password input
if not args.password.strip():
print("Error: Database password cannot be empty.")
sys.exit(1)
# connect to database
try:
db.connect(args.password)
# main loop: get games for player and analyze each
for row in db.get_games(args.IdPlayer):
analyse_game(row[0])
db.rollback()
db.disconnect()
engine.quit()
except Exception as e:
logging.error(f"Fatal error: {e}")
try:
db.disconnect()
except:
pass
engine.quit()
sys.exit(1)
if __name__ == "__main__":
main()
Den Datenbank-nahen Programmcode mit den SQL-Anweisungen haben wir in das Modul chessdb.py ausgelagert.
Python Code
from datetime import date
from datetime import time
from dataclasses import dataclass
import mariadb
conn = None
cursor = None
@dataclass
class PositionAnalysisRecord:
position_id: int = None
centipawn: int = None
wins: int = None
draws: int = None
losses: int = None
best_move_uci: str = ""
depth: int = None
seldepth: int = None
nodes: int = None
time_sec: float = None
def connect(p_password):
global conn
global cursor
if conn != None and conn.open:
return
# Database connection details
db_config = {
"user": "chess_user",
"password": p_password,
"host": "localhost",
"database": "chess",
"port": 3306, # Standard port for MariaDB
}
# Establishing the connection
conn = mariadb.connect(**db_config)
# Disable autocommit
conn.autocommit = False
# Create a cursor to execute queries
cursor = conn.cursor()
def disconnect():
cursor.close()
conn.close()
def commit():
conn.commit()
def rollback():
conn.rollback()
def insert_position_analysis(p_position_analysis):
cursor.execute(
"insert into position_analysis (position_id, centipawn, wins, draws, losses, best_move_uci, depth, seldepth, nodes, time_sec) values (?,?,?,?,?,?,?,?,?,?)",
(
p_position_analysis.position_id,
p_position_analysis.centipawn,
p_position_analysis.wins,
p_position_analysis.draws,
p_position_analysis.losses,
p_position_analysis.best_move_uci,
p_position_analysis.depth,
p_position_analysis.seldepth,
p_position_analysis.nodes,
p_position_analysis.time_sec,
),
)
def get_games(p_id_player):
cursor.execute(
"select id from game where white_player_id=? or black_player_id=? order by game_date, id",
(
p_id_player,
p_id_player,
),
)
return cursor.fetchall()
def position_analysis_exists(p_game_id):
cursor.execute(
"select count(*) from game g where g.id = ? and exists (select 1 from position p join position_analysis pa on (p.id = pa.position_id) where p.game_id = g.id )",
(p_game_id,),
)
row = cursor.fetchone()
return row[0] > 0
def get_positions(p_game_id):
sql = """
select
t.pos_id,
t.new_position
from
(
select
g.game_date,
pos.id pos_id,
pos.half_move_num,
pos.fen "new_position",
NVL(LAG(pos.fen) over (order by pos.half_move_num), 'rnbqkbnr/pppppppp/8/8/8/8/PPPPPPPP/RNBQKBNR w KQkq - 0 1') as 'prior_position'
from
game g
join position pos on
pos.game_id = g.id
where
g.id = ?
) t
where
not (exists (
select
1
from
fen_history h
where
h.fen_pos = REGEXP_SUBSTR(t.new_position, '[^ ]+ [^ ]+ [^ ]+ [^ ]+')
and h.game_date < t.game_date)
and exists (
select
1
from
fen_history h
where
h.fen_pos = REGEXP_SUBSTR(t.prior_position, '[^ ]+ [^ ]+ [^ ]+ [^ ]+')
and h.game_date < t.game_date))
order by
t.half_move_num
"""
cursor.execute(sql, (p_game_id,))
return cursor.fetchall()
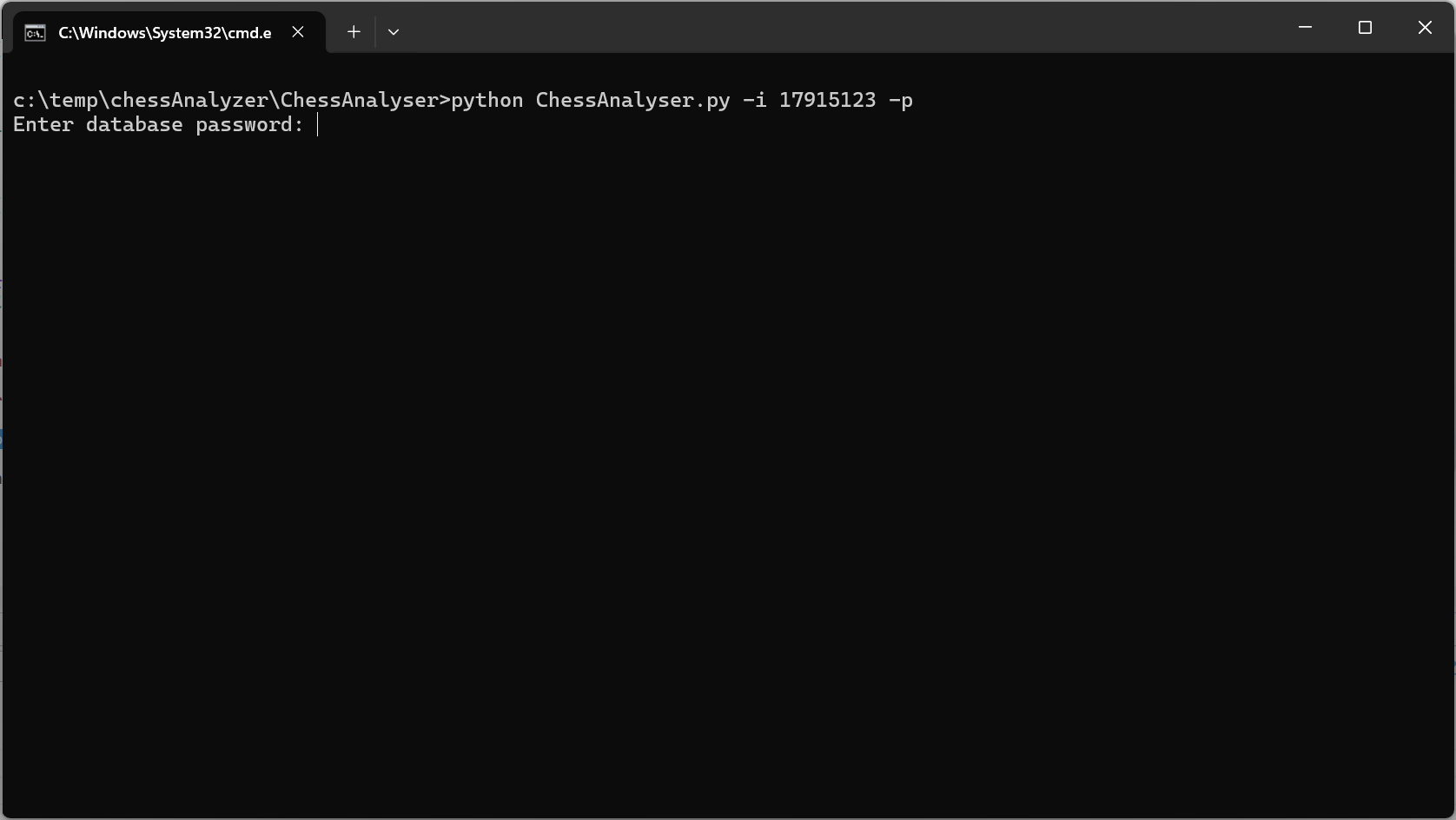
Wir können nun unseren geplanten Testlauf absolvieren und starten das Programm in einer Windows-Eingabeaufforderung („cmd.exe“) mit den beiden Parametern IdPlayer und password. Den Wert für das Datenbankpasswort geben wir dabei nach Aufforderung verdeckt ein.
Während des Programmlaufs sehen wir uns die Systemauslastung für CPU und Hauptspeicher im Windows Taskmanager an.
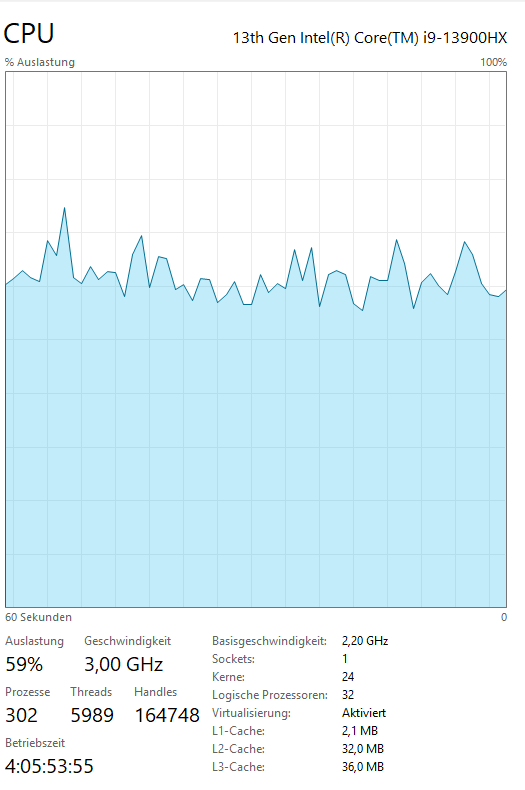
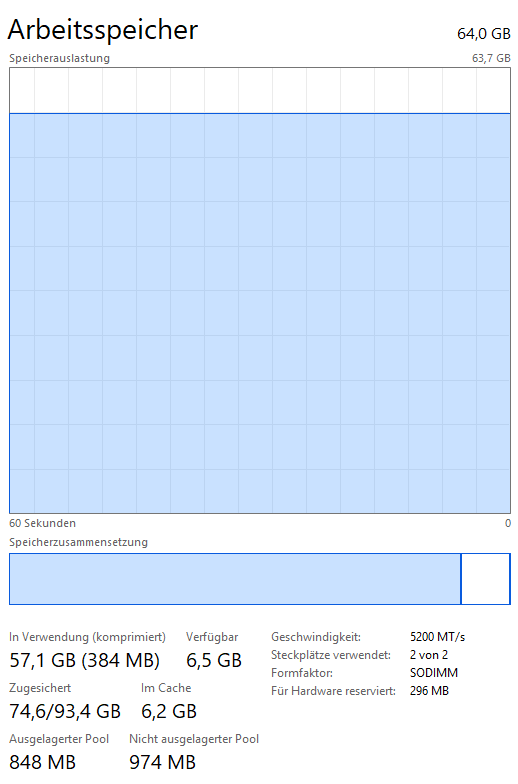
Nach Programmende prüfen wir die erzeugten Positions-Kennzahlen und internen statistischen Werte der chess engine mit einer entsprechenden SQL-Abfrage.
SQL-Code
select
g.id "Game ID",
pw.name white,
pb.name black,
p.half_move_num,
coalesce(nullif(p.move_white, '') , p.move_black ) move,
pa.best_move_uci,
pa.centipawn,
pa.wins,
pa.draws,
pa.losses ,
pa.depth,
pa.seldepth ,
pa.nodes,
pa.time_sec
from
game g
join player pw on
g.white_player_id = pw.id
join player pb on
g.black_player_id = pb.id
join position p on
(g.id = p.game_id)
join position_analysis pa on
(p.id = pa.position_id)
where
pw.id = 17915123
or pb.id = 17915123
order by
g.id,
p.half_move_num;
Insgesamt handelt es sich dabei um 377 einzelne Einträge in der Tabelle position_analysis. Ebenfalls schön zu sehen ist im obigen Bild, dass bei der anfänglichen Partie die Analyse erst beim achten Halbzug (vierter Zug von Schwarz) beginnt. Die Analyse der zweiten Partie entsprechend erst beim elften Halbzug. Offenbar funktioniert auch der Lookup in die Stellungshistorie, mit dem sichergestellt wird, dass nur neuartige Positionen einer Bewertung unterzogen werden.
Wenn wir das Programm nun ein zweites Mal starten, erwarten wir, dass es erkennt, dass die Spiele bereits analysiert wurden und sie deshalb überspringt. Die Zahl der Einträge sollte unverändert bleiben. Das korrekte Verhalten entnehmen wir der Log-Datei.
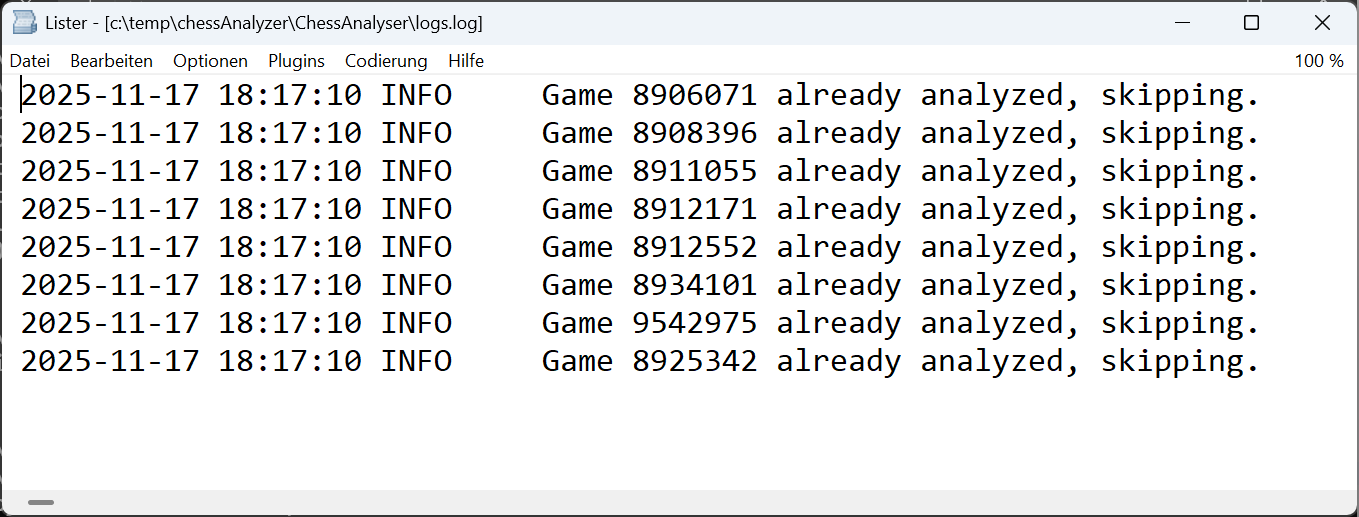
Im nächsten Kapitel versuchen wir, möglichst viele Partien einiger bekannter Schachgrößen zu analysieren und sind auf die Laufzeiten gespannt…